
Тест GeForce RTX 5080 у порівнянні з RTX 4080, RTX 4090 та RX 7900 XTX: знайомство з NVIDIA Blackwell
02-06-2025
У цьому огляді протестуємо новинку 50-ї серії NVIDIA: розповімо, як вона влаштована з середини, ознайомимось із архітектурними особливостями і звісно поганяємо у іграх та порівняємо з декількома швидкими опонентами.
Щоб трішки вшанувати роки кропіткої роботи інженерів, спочатку проведемо дослідження внутрішнього устрою лінійки. І тут слід уточнити, що уся подальша інформація буде стосуватись повного чипу GB202, який навіть у RTX 5090 не використовується.
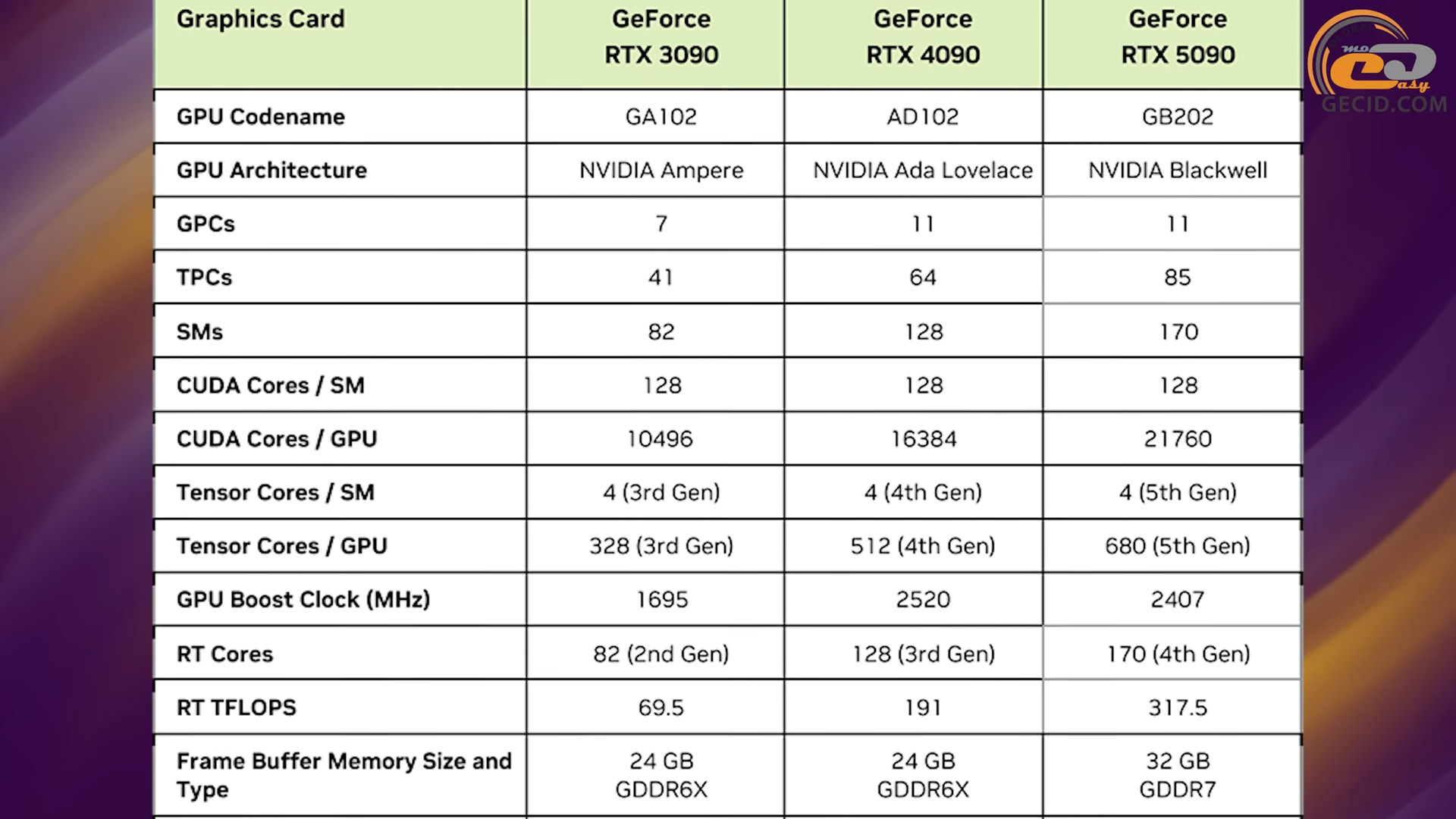
Виготовляється він по технологічному процесу TSMC 4NP, який насправді є удосконаленими 5-ма нанометрами. Через це загальна кількість транзисторів між поколіннями сильно уповільнила свій темп зростання - менш ніж 21%. Для порівняння, перехід від 8 нанометрів 30-ї серії до 5 нанометрів 40-ї, супроводжувався нарощуванням транзисторного бюджету більш ніж у 2,5 рази! Тільки ці цифри вже викликають занепокоєння, але не будемо робити завчасних висновків.
Виконавчий блок
Архітектура нового покоління отримала назву NVIDIA Blackwell на честь американського математика і за своєю структурою є вдосконаленою версією GPU останніх поколінь.

На фізичному рівні виконавчої частини GPU збільшилась кількість майже усіх основних елементів. У порівнянні з повним чипом Ada Lovelace 40-ї лінійки чисельність CUDA ядер зросла з 18432 до 24576, текстурних конвеєрів та тензорних ядер - з 576 до 768, ядер для обробки трасування променів - з 144 до 192 (відповідно до кількості SM-блоків). А от модулів растеризації залишилось 192, як і в попередньому поколінні. Також варто зазначити наявність 384 ядер для обробки 64-розрядних чисел з рухомою комою, які не вказано на діаграмі, але потрібні для сумісності з певним програмним забезпеченням.
Основною домінуючою високорівневою апаратною сутністю у всіх графічних процесорах сімейства є 12 графічних процесорних кластерів (скорочено GPC) структуру яких Ви бачите на екрані. Кожен з них складається з 8 кластерів для обробки текстур (TPC), 16-ти SM-блоків та 16 блоків ROP.
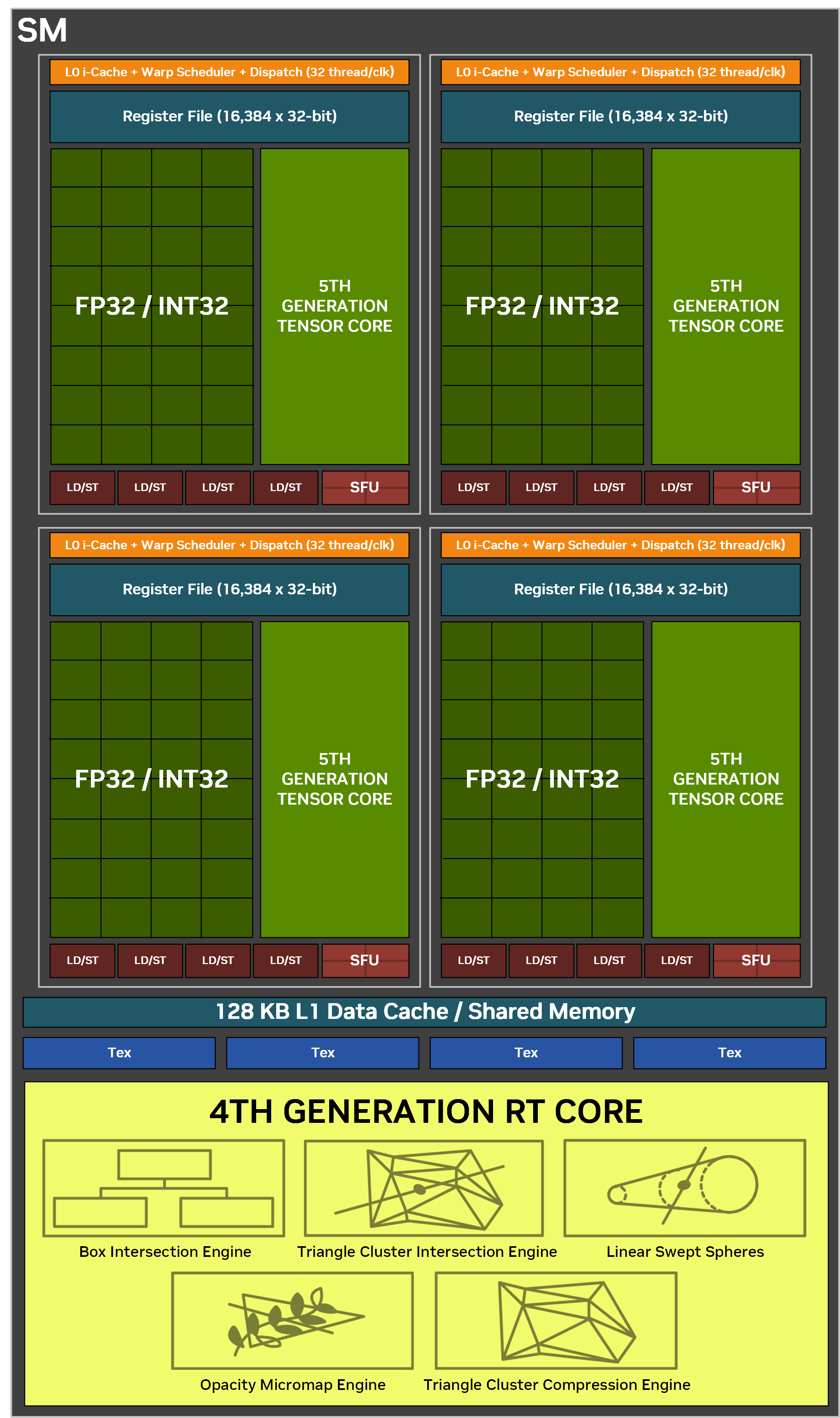
У свою чергу кожен SM-блок відіграє ключову роль при паралельній обробці обчислень на різних за своїм призначенням ядрах - CUDA, тензорних та RT. Перших у його складі налічується 128 штук, других чотири і третіх по одному. Також тут розміщується 256-кілобайтний регістровий кеш та 128-кілобайтний кеш першого рівня, який, як ми зрозуміли, може автоматично ділитись на менші за обсягом сегменти пам’яті в залежності від типу навантаження.
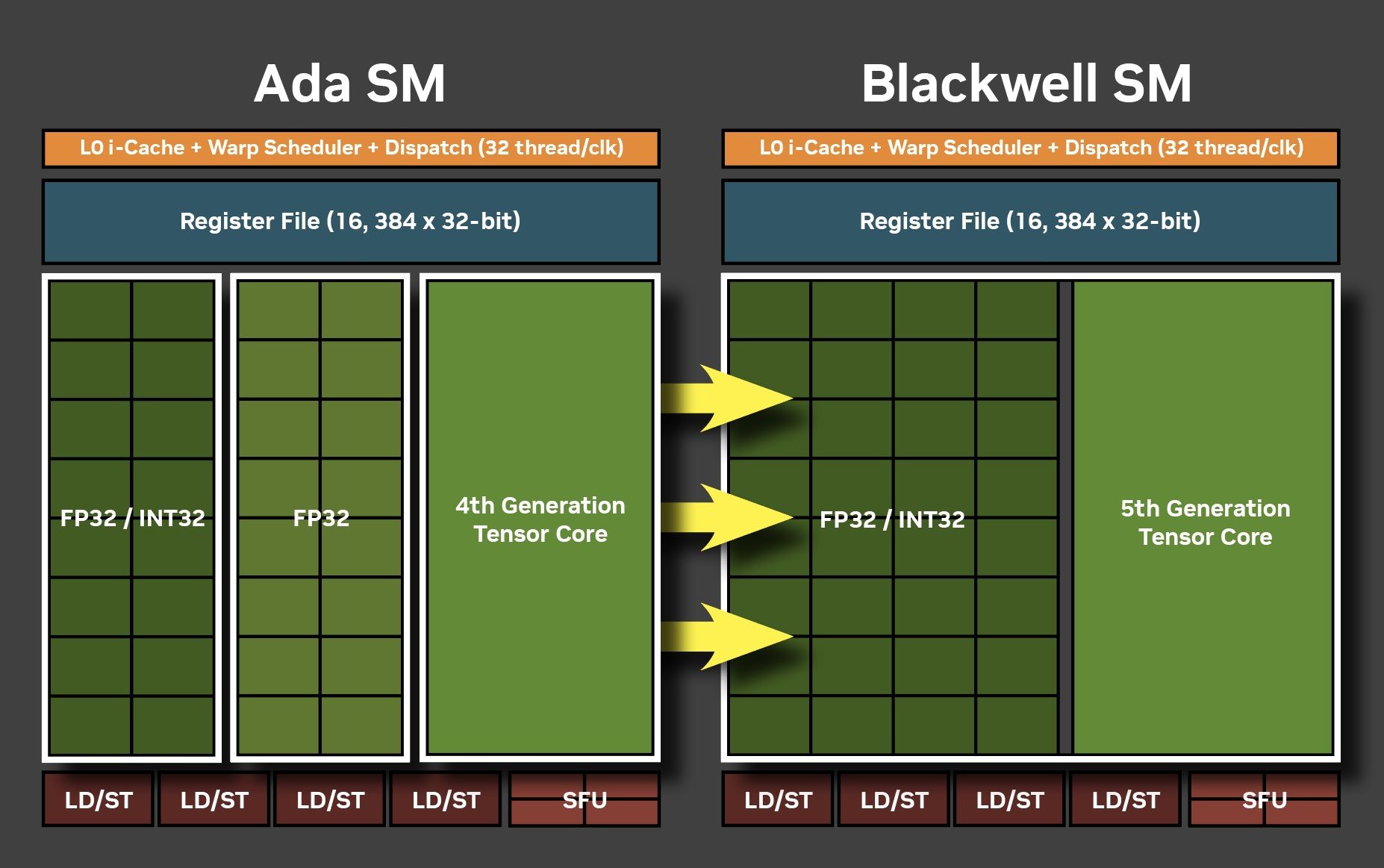
Суттєво змінилась у новому поколінні і логіка роботи з різними типами даних. В порівнянні із Ada Lovelace, архітектура Blackwell подвоїла обробку операцій над цілими числами. Але тут є хитрість - раніше половина SM-блоків у кластері GPC могла паралельно працювати як з дійсними, так і з цілими числами, а тепер на окремо взятому такті GPU це можуть бути виключно числа або першого, або другого типу даних.
Останнім удосконаленням у виконавчий частині чипу є кеш другого рівня. Він у порівнянні з попереднім поколінням збільшився з 96 до 128 МБ.
VRAM
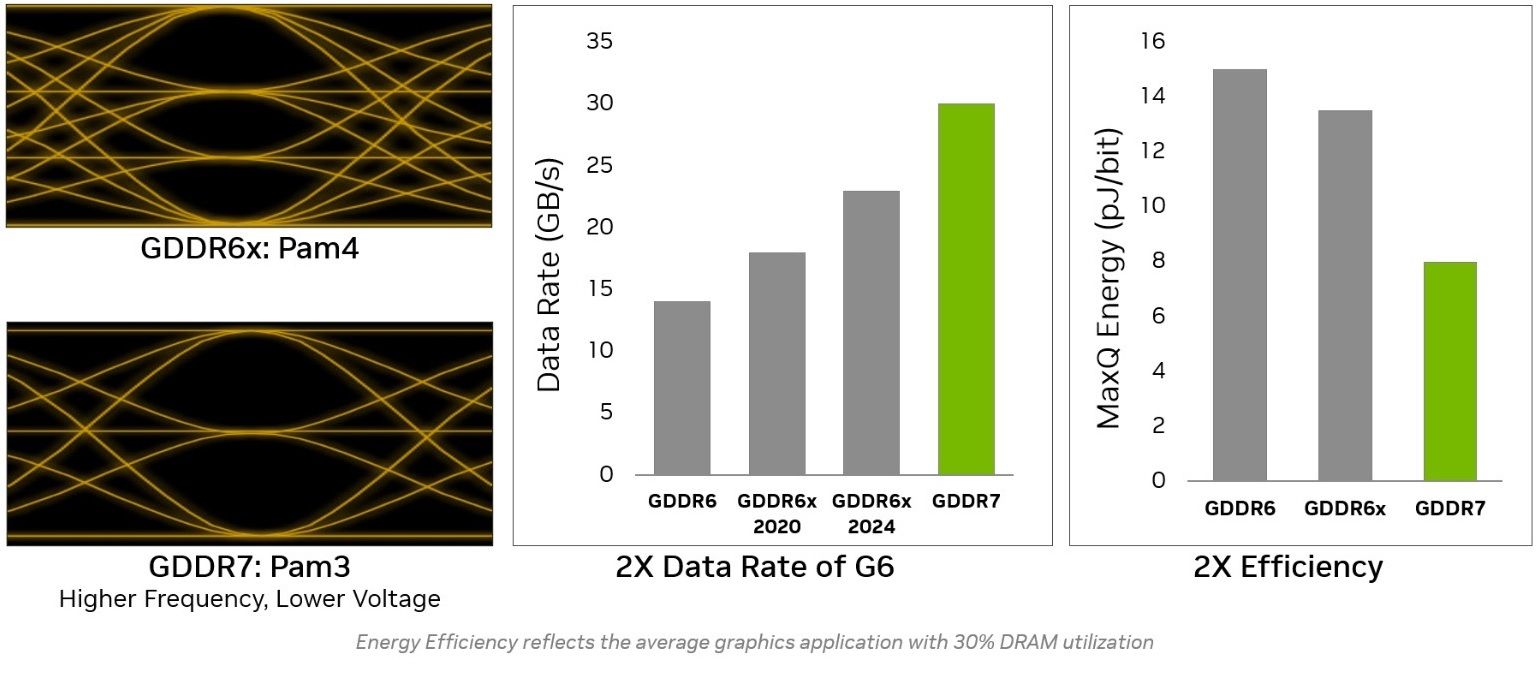
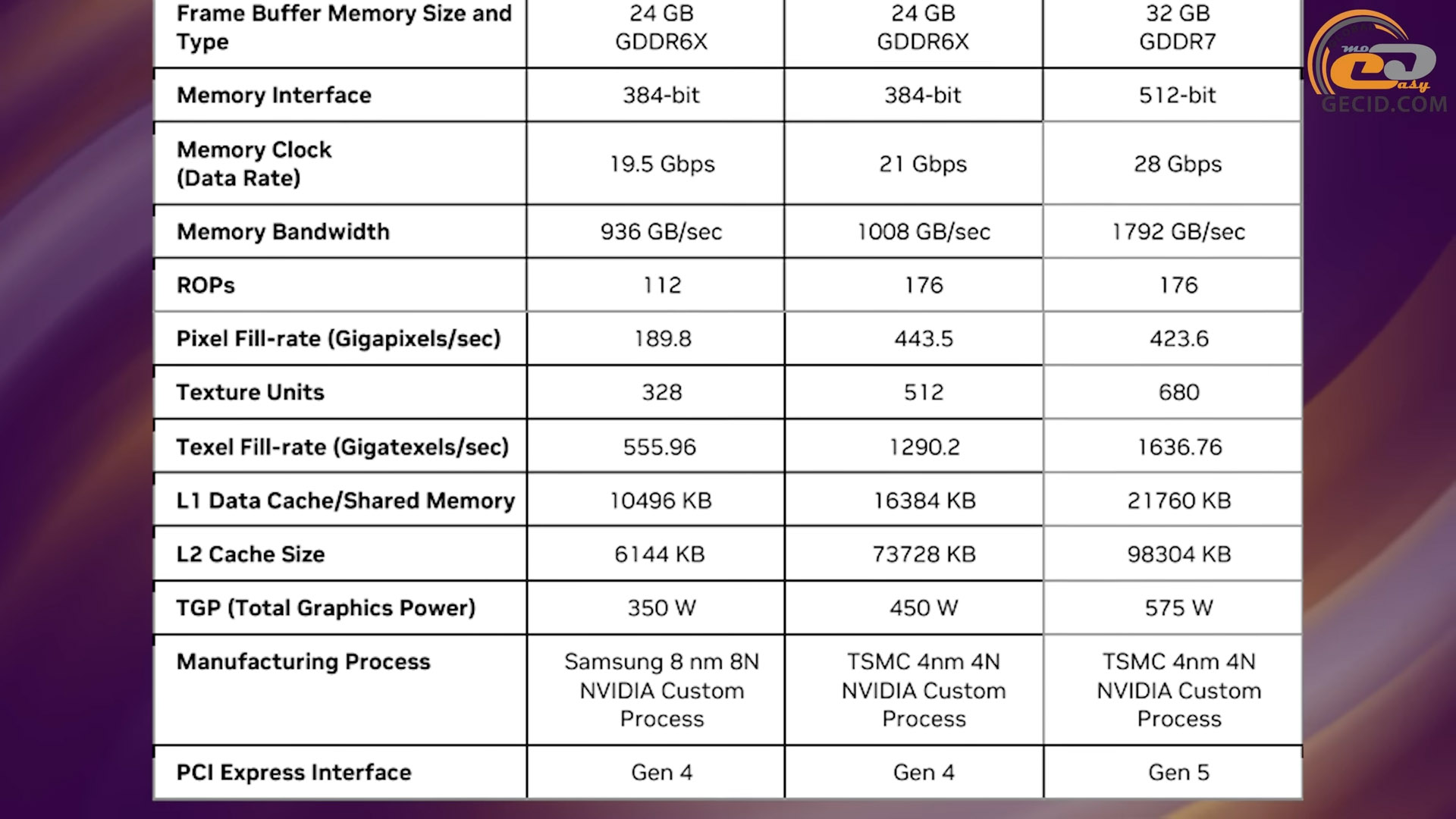
На другому місці серед апгрейдів йде новий тип відеопам’яті – GDDR7. У порівнянні із найшвидшою VRAM минулого покоління, GDDR6X, суттєво змінився сам спосіб передачі даних. Якщо попереднє покоління використовувало амплітудно-імпульсну модуляцію з чотирма рівнями сигналу (скорочено PAM4), передаючи два біти за один цикл звернення до відеобуферу, то нове покоління може відрізняти три рівні сигналу (PAM3) і передавати при цьому півтора біт за цикл. Спочатку може здатися, що перший варіант швидший за другий, але не все так просто. Річ у тому, що PAM4 погано даються ефективні частоти вище 22,5 гігабіт за секунду на контакт через високу чутливість до співвідношення сигнал/шум. PAM3 в поєднанні з інноваційною схемою декодування справляється із цією проблемою краще, тому і частоти передачі даних їй доступні вищі – на даний момент до 30 гігабіт за секунду. Ще додаємо до цього покращену роботу із введенням/виведенням та 512-бітну шину, якої ми вже дуже давно не бачили у картах NVIDIA, і отримуємо майже 1,8 терабайти за секунду загальної пропускної здатності проти 1-го терабайту за секунду у попередньому поколінні. Також відповідні графіки натякають, що такий підхід ще й енергоефективність покращив майже до двох разів у порівнянні зі звичайною GDDR6 і на декілька десятків відсотків із її «Іксовою» модифікацією.
Тензорні ядра
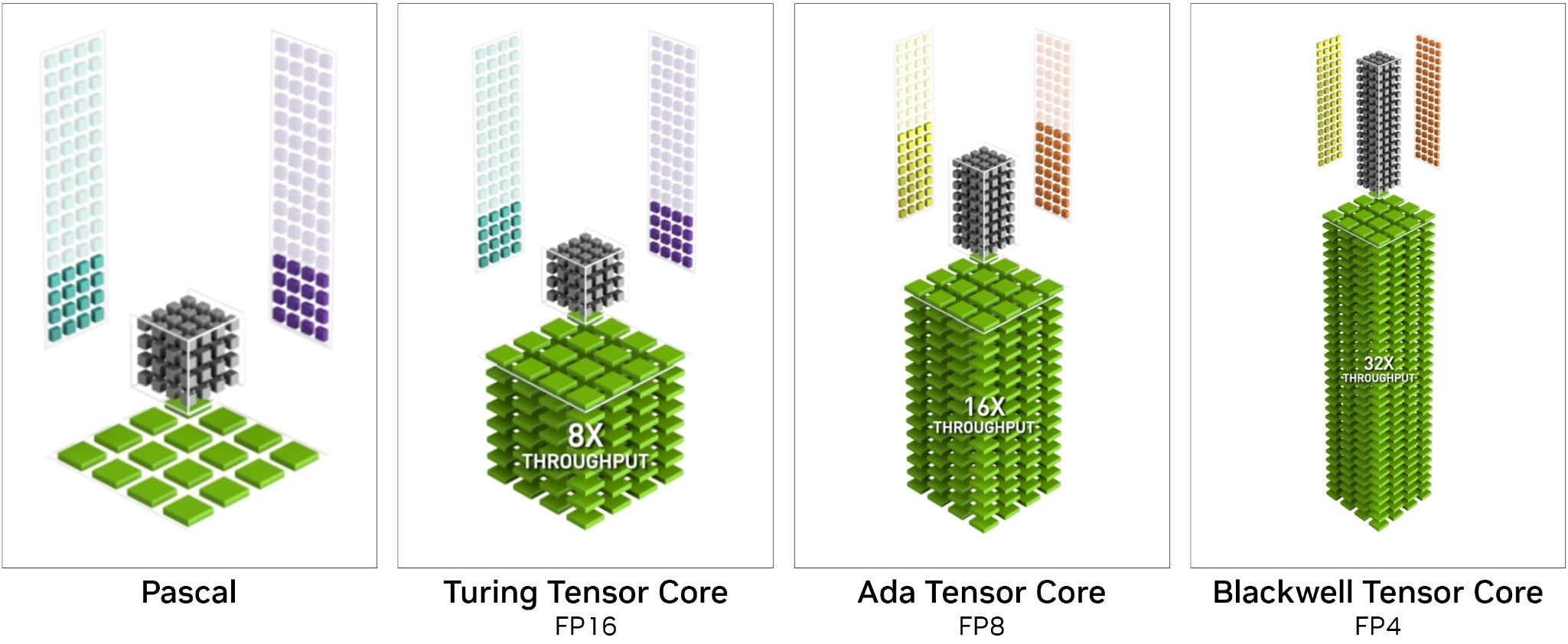
Оновились у Blackwell і тензорні ядра, основним призначенням яких є операції над матрицями. Особливо часто вони використовуються у алгоритмах машинного навчання та таких технологіях як масштабування зображення за допомогою штучного інтелекту і генерація кадрів. Еволюціонували вони до п’ятого покоління і вперше отримали підтримку операцій з низькою точністю над 4-рьох та 6-розрядними числами з рухомою комою. Зроблено це для економії VRAM генеративними AI-моделями, які за час існування суттєво збільшили свої можливості, але і місця стали потребувати більше. А чим менше бітність представлення чисел, тим менше пам’яті потрібно для їх зберігання. Як приклад, фахівці NVIDIA провели експерименти з моделлю FLUX.dev від Black Forest Labs, яка може генерувати зображення за текстовим описом, і заявляють про більш ніж двократну економію відеобуферу при використанні 4-бітного формату чисел у порівнянні із 16-бітним. При цьому важлива і швидкість обробки – з FP16 процес генерації проекту відбувався втричі довше.
RT-ядра
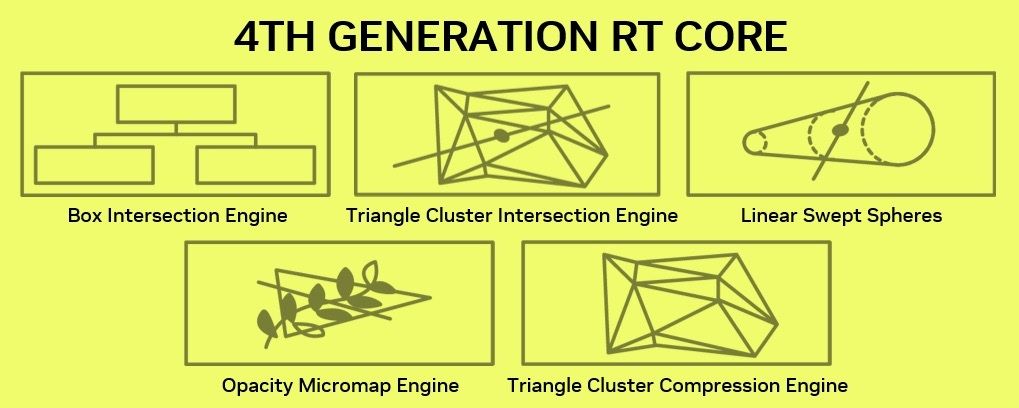
Удосконалення отримали і RT-ядра, які оновилися до четвертої генерації. Основним із них є подвоєна швидкість обробки перетинань променями полігонів за такт. Дана операція є одною із найресурсоємніших у процесі трасування, тож слід очікувати значного приросту продуктивності нового GPU по даному напрямку.
Та не тільки за допомогою «сирої» продуктивності компанія NVIDIA збирається боротися із неповороткістю рейтрейсингу. Цілий набір інноваційних програмних інструментів Mega Geometry має допомогти чипам NVIDIA вести відповідні розрахунки ще швидше.

І тут слід трішки уточнити що таке структура-дерево BVH, бо більшість удосконалень стосується саме неї.
Створено останню для спрощення розрахунку зіткнень 3D-об’єктів між собою чи перетину їх променями у реальному часі. Адже перевірка з високою частотою колізій сотень або навіть тисяч примітивів, з яких складаються кінцеві об’єкти, перевищить можливості будь-якого сучасного прискорювача. А розбивши кожен такий об’єкт послідовно на все менші і менші частини, з’являється можливість суттєво зекономити обчислювальні ресурси. У випадку променів, GPU перевіряє на перетинання найвищий за рівнем елемент BVH і якщо воно є, то спускається нижче по дереву та визначає з якими саме дочірніми частинами структури промені зіштовхнулись, усі інші елементи (ті із якими контакту не виникло) відкидаються і, відповідно, не прораховуються.
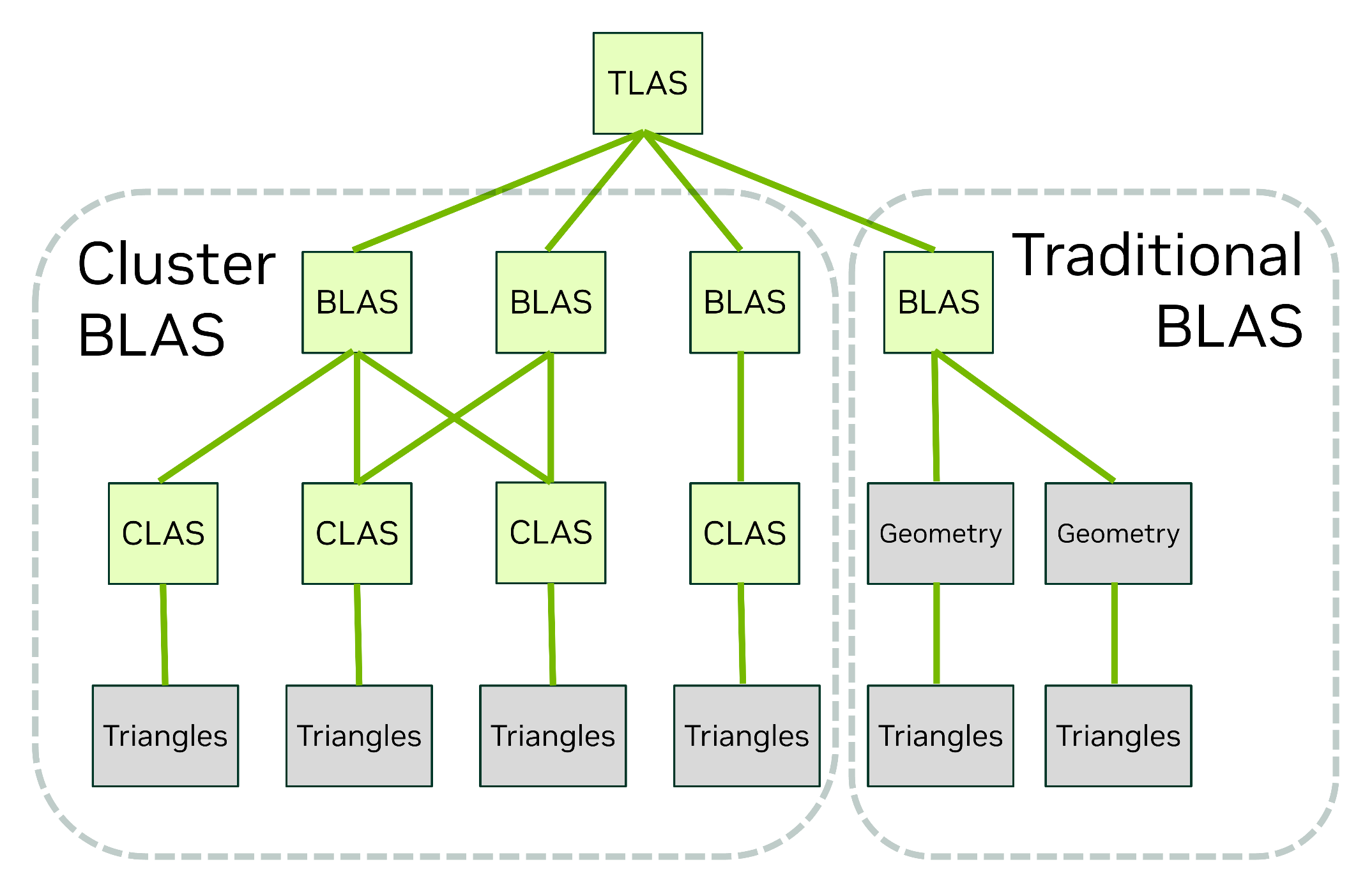
Так от, по-перше, з’явився новий тип примітивів у дереві BVH під час RT-рендерингу - Cluster-level Acceleration Structures (скорочено CLAS). Він на два порядки пришвидшує побудову структур, коли об’єкти, для яких вони створюються, змінюють координати розташування відносно точки огляду.
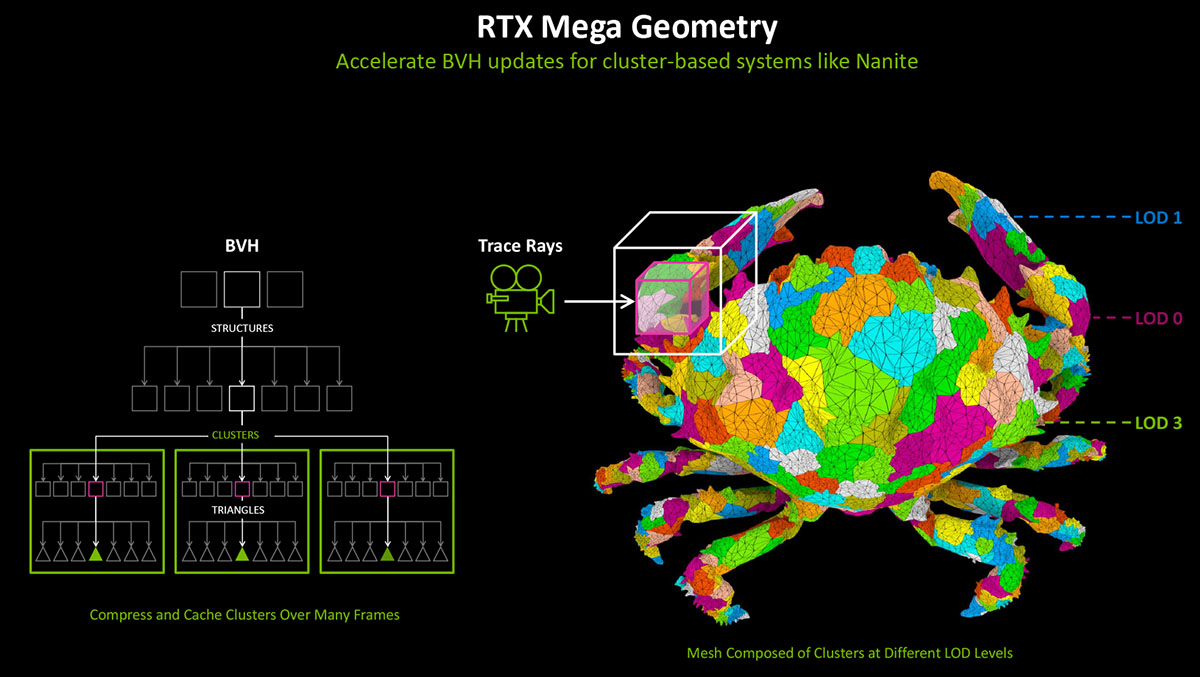
По суті, це кеш із груп полігонів, який використовує дані попереднього кадру для оптимізації наступних. Особливу користь від такого підходу має отримати система віртуальної геометрії Nanite у Unreal Engine 5.

По-друге, змінився принцип побудови статичних структур високого рівня у дереві BVH. Якщо раніше у кожному наступному кадрі такі структури створювались заново, то із переходом на Mega Geometry вони розбиваються на частини нижчого рівня один раз, а далі відокремлюються від аналогічних за рангом динамічних структур і відправляються у окремий кеш для використання у наступних кадрах.

І дійсно, навіщо у кожному кадрі заново створювати, наприклад стіну будинку, якщо рушію відомо, що у наступних кадрах вона нікуди не дінеться. Новий тип структури отримав назву Partitioned Top-Level Acceleration Structure (PTLAS).
І тут добра новина - технологія Mega Geometry підтримується на усіх RTX прискорювачах NVIDIA починаючи з покоління Turing.
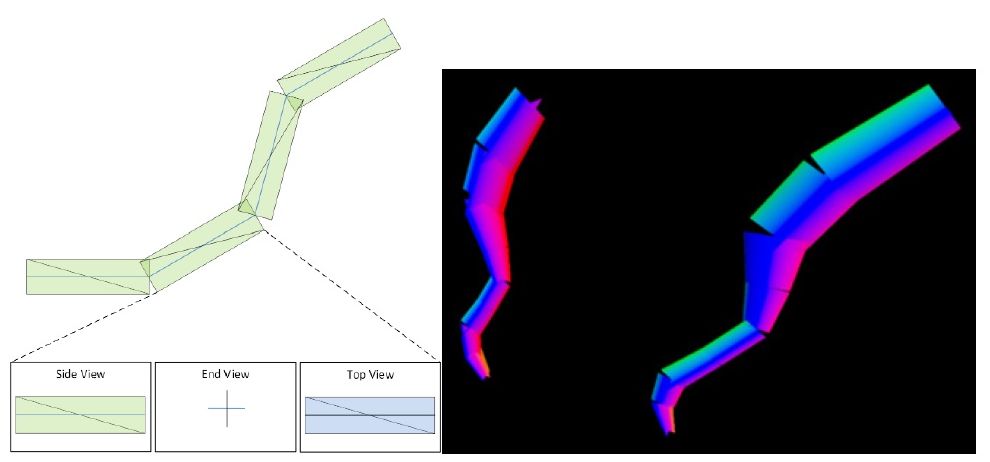
Йдемо далі і торкнемося теми, яку після виходу третього відьмака, мабуть всі вже і забули – 3D-волося, хутро і аналогічні об’єкти. RT-ядра у поколінні Blackwell на апаратному рівні спроможні співпрацювати із новим видом примітивів - Linear Swept Spheres (скорочено LSS), а також виконувати перевірку перетинання їх променями. Основні зміни тут криються у способі представлення меш-об’єктів.
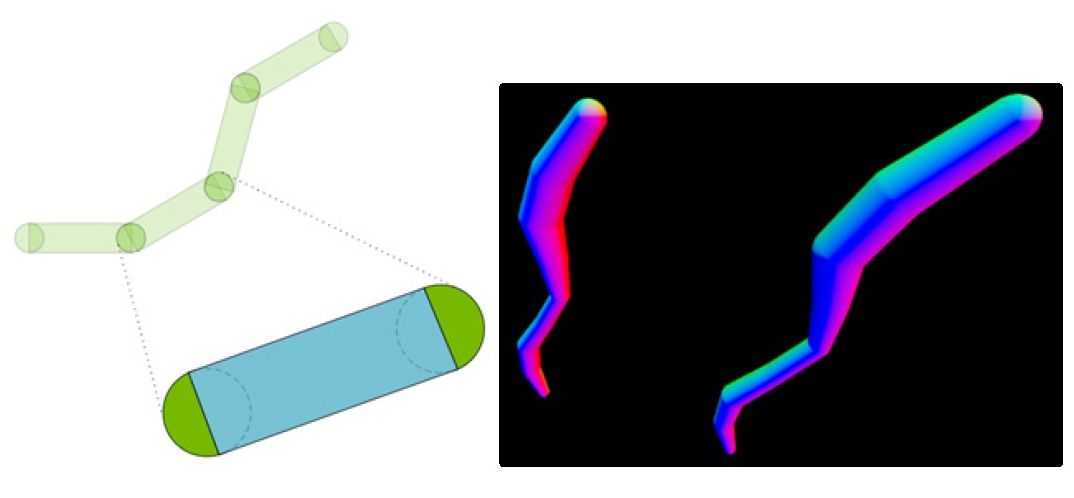
Із LSS кожна волосинка створюється не за допомогою полігонів і прямокутних сегментів, як це було раніше, а за допомогою сфери, яка «рухаючись» від початку до кінця об’єкту і, змінюючи діаметр, формує циліндричні сегменти.
Планувальники

Відволічемось від променів і звернемо увагу на те, як GPU працює із різнорідними обчисленнями. Механізм Shader Execution Reordering оновився до версії 2.0 і отримав декілька апаратних та програмних удосконалень, які мають вдвічі покращити функцію динамічного сортування потоків даних на різні типи ядер. Більш детальної інформації виробник не розкриває, але відомо, що за допомогою спеціального API розробники програмного забезпечення зможуть самостійно перенаправляти потоки даних на потрібні обчислювачі для більш оптимально їх виконання.
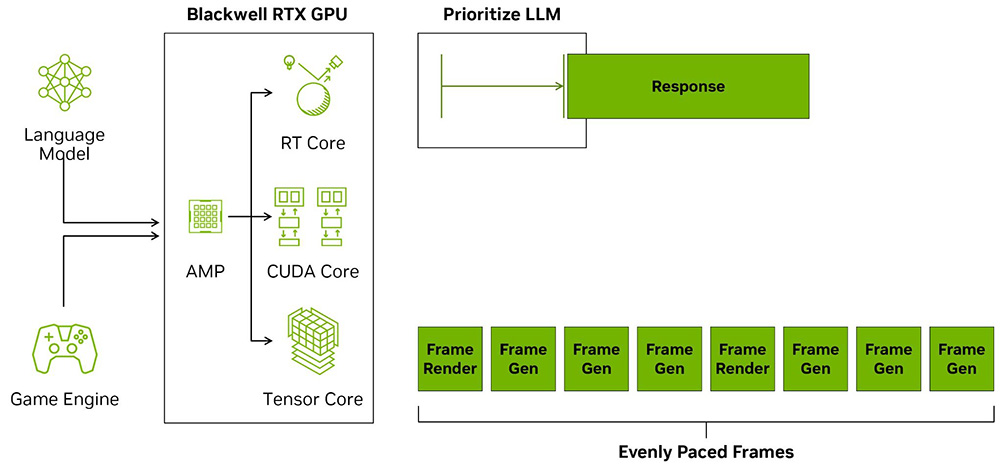
Також варто згадати про ще один оновлений планувальник - AI Management Processor (скорочено AMP). Він апаратно реалізований за допомогою спеціального RISC-V процесора, розташованого перед усіма обчислювальними конвеєрами GPU. Основним його завданням є менеджмент системних процесів, виконання яких так чи інакше пов’язано з відеокартою. Такий підхід суттєво зменшує навантаження на центральний процесор, адже раніше цю роботу виконував саме він. На програмному рівні AMP взаємодіє із вшитою у Windows 10 та 11 технологією HAGS (Hardware-Accelerated GPU Scheduling).
Медіа рушій
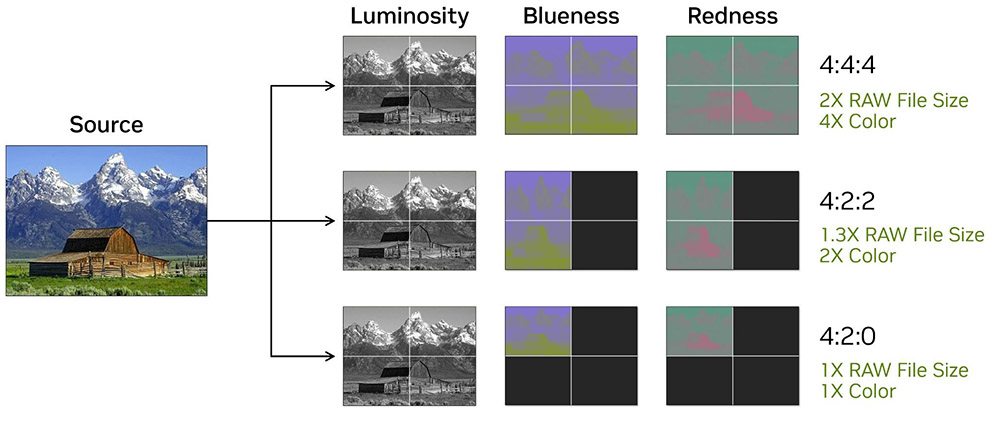
Ще з новенького у архітекутрі Blackwell відмітимо появу апаратної підтримки кодування та декодування відео у форматі YUV 4:2:2 для відеокодеків H.264 та H.265, а також збільшення швидкості декодування H.264 вдвічі та режим Ultra High Quality для AV1.

До того ж DisplayPort версії 2.1b має збільшити пропускну здатність відеопотоку до 80 гігабіт за секунду, що має підняти планку роздільної здатності та частоти до 8K при 165 Гц.
Енергоефективність
Оскільки технологічний процес виробництва чипів 50-ї лінійки змінився не суттєво, а кількість транзисторів дещо зросла, чималу увагу розробникам довелося приділити енергоефективності. Зокрема концепції Max-Q, яка отримала декілька важливих удосконалень.

Першим із них є можливість відключення певних частин чипу від тактового генератора, якщо вони простоюють, не довантажені, або ще не встигли змінити активний статус роботи на пасивний. З цією ж метою живлення GPU-ядер і відеобуферу розділили на окремі лінії.
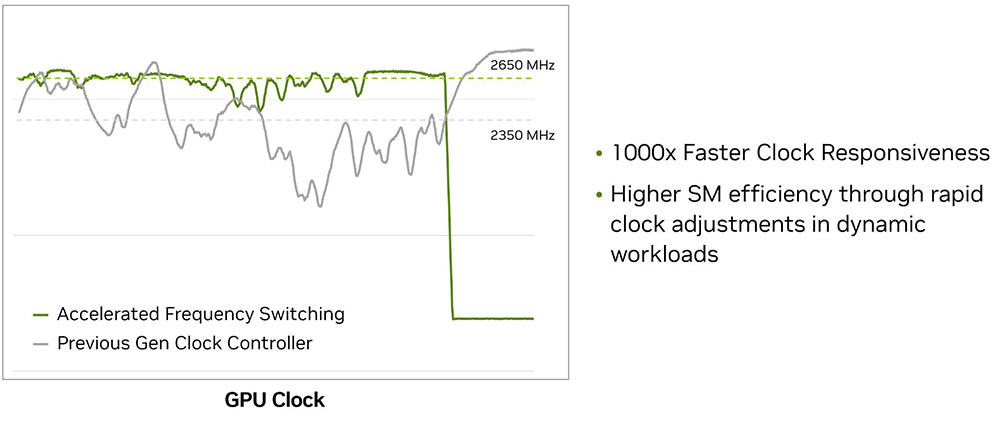
Другою інновацією є значно швидше перемикання робочої частоти чипа, яке у 1000 разів перевищує показники 40-ї серії. Раніше частота динамічно змінювалася, але зрештою підлаштовувалася під окремий кадр. Тепер же вона може суттєво варіюватися прямо під час його рендерингу.
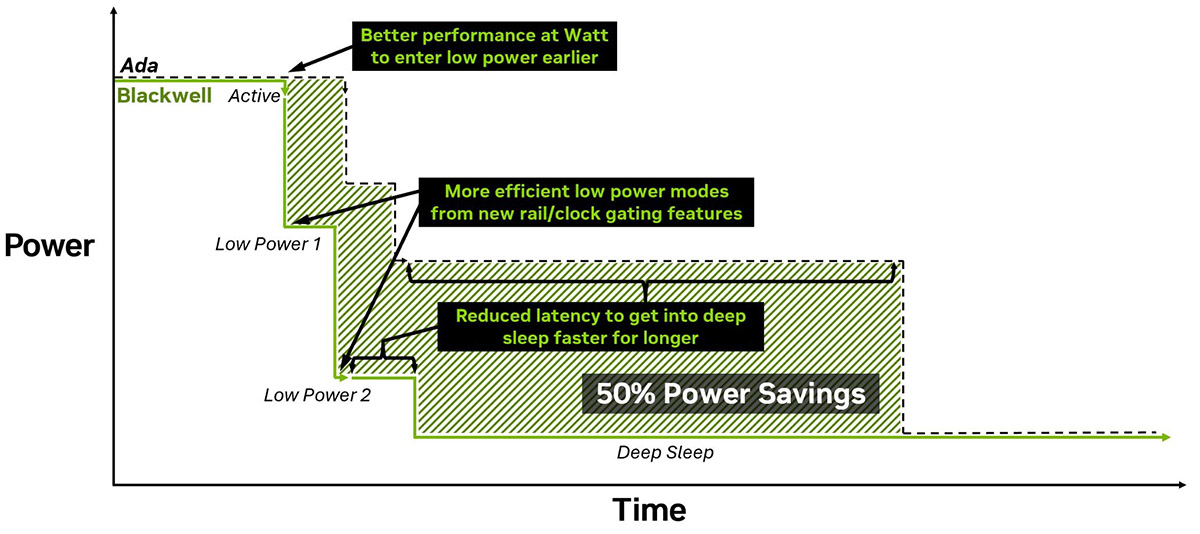
Наостанок, NVIDIA заявляє, що Blackwell переходить у режим глибокого сну в 10 разів швидше, ніж попереднє покоління. Це дозволяє заощадити до 50% енергії в окремих завданнях, наприклад, під час генерації тексту невеликими мовними моделями.
DLSS 4
Одразу попередимо, що технологію DLSS четвертого покоління, яку використовує 50-та лінійка, ми детально розглянемо в одному з наступних матеріалів. Тут зупинимось лише на її ключових особливостях.
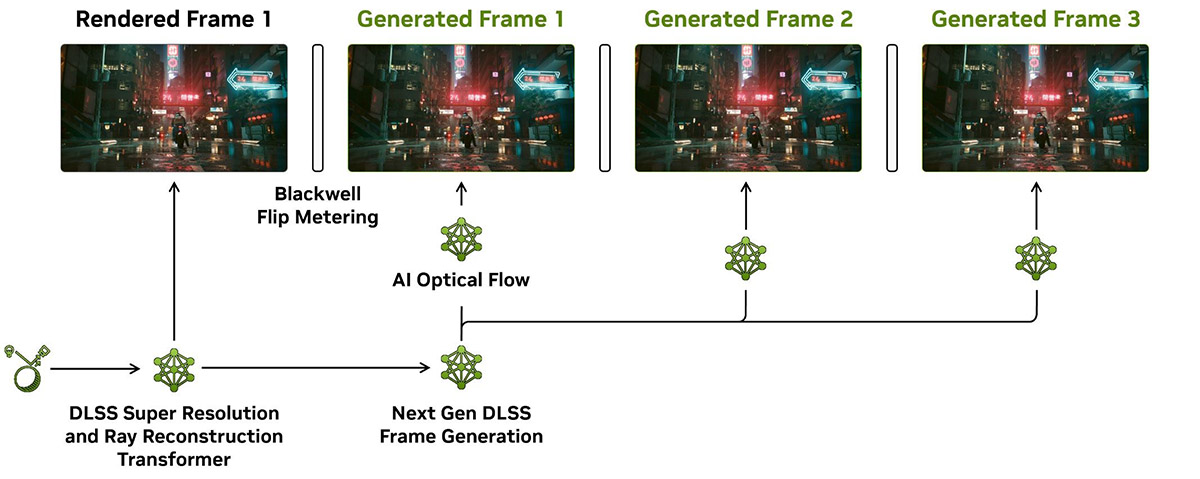
Вже не секрет, що з DLSS 4 карти NVIDIA можуть генерувати не один, а одразу до трьох додаткових кадрів на кожен чесно візуалізований . Це стало можливим завдяки кардинально зміненому підходу до роботи технології. Якщо раніше відстеження потоку зміни кадрів виконувалося на апаратному рівні, то тепер за це відповідає окрема нейромережа, яка і працює на 40% швидше, і споживає на 30% менше VRAM.

Щоб збільшена кількість згенерованих кадрів не спричинила значний input lag, оновлення отримала і добре знайома технологія Reflex, піднявшись до версії 2.0. Тепер перед виведенням останнього згенерованого кадру на дисплей спочатку перевіряються дані з пристроїв вводу. Відповідно до отриманої інформації відбувається корекція, і лише після цього кадр відправляється на екран.

Ще одним терміном, до якого доведеться звикати у новому поколінні відеокарт є модель Transformer. Простими словами, це новий підхід до розпізнавання та класифікації первісних зображень за допомогою нейромережі для подальшого створення нових зображень. Така обробка критично важлива для DLSS Super Resolution, DLSS Ray Reconstruction та Deep Learning Anti-Aliasing (DLAA).
У попередньому поколінні застосовувалася модель Convolutional Neural Network (CNN), яка аналізувала зображення великими фрагментами. Натомість модель Transformer працює точніше – попіксельно, забезпечуючи вищу якість, деталізацію та чіткість ціною незначної втрати продуктивності.
Нейронні шейдери
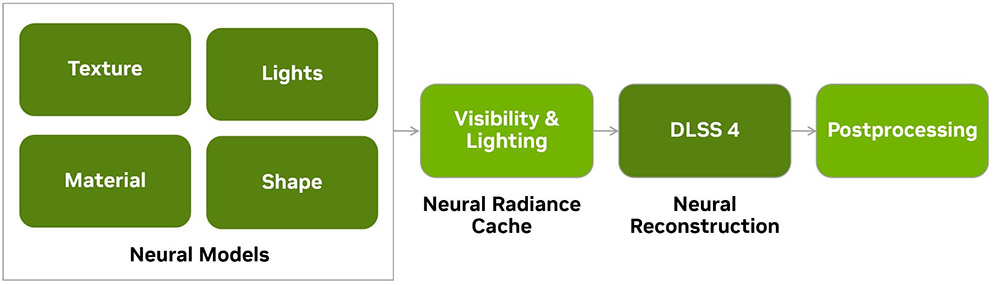
Останній, але не менш важливий акцент від NVIDIA — нейронні шейдери, які, на наш погляд, мають не менше значення, ніж мультифрейм-генерація.
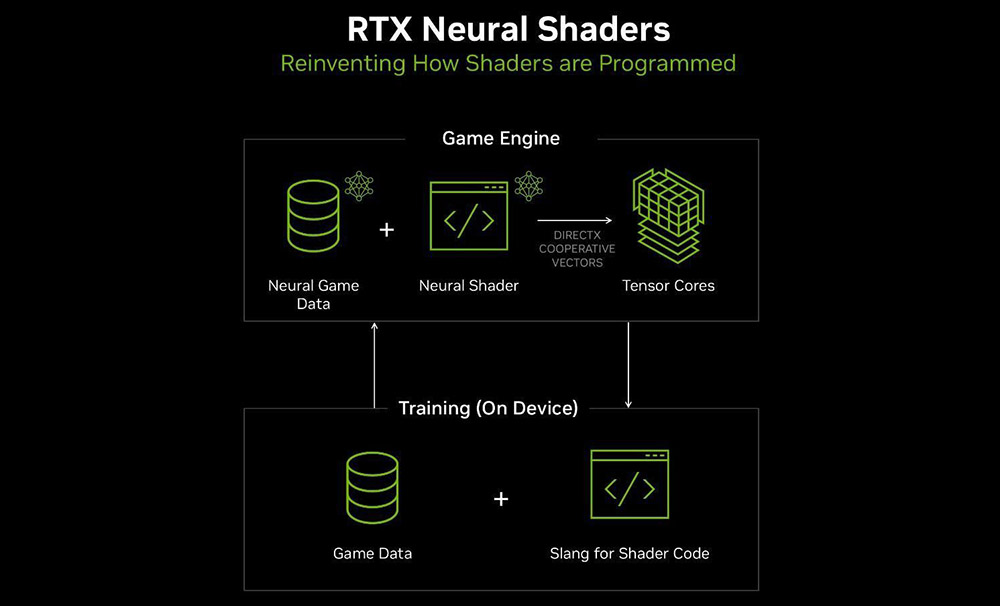
Компанія повідомляє, що у майбутньому традиційні шейдерні обчислення на CUDA-ядрах поступово перейдуть на тензорні ядра та локальні нейромережі. Вже зараз лінійка RTX 50 може запропонувати три напрямки, де цей підхід забезпечить приріст продуктивності: RTX Neural Texture Compression, RTX Neural Materials та Neural Radiance Cache.
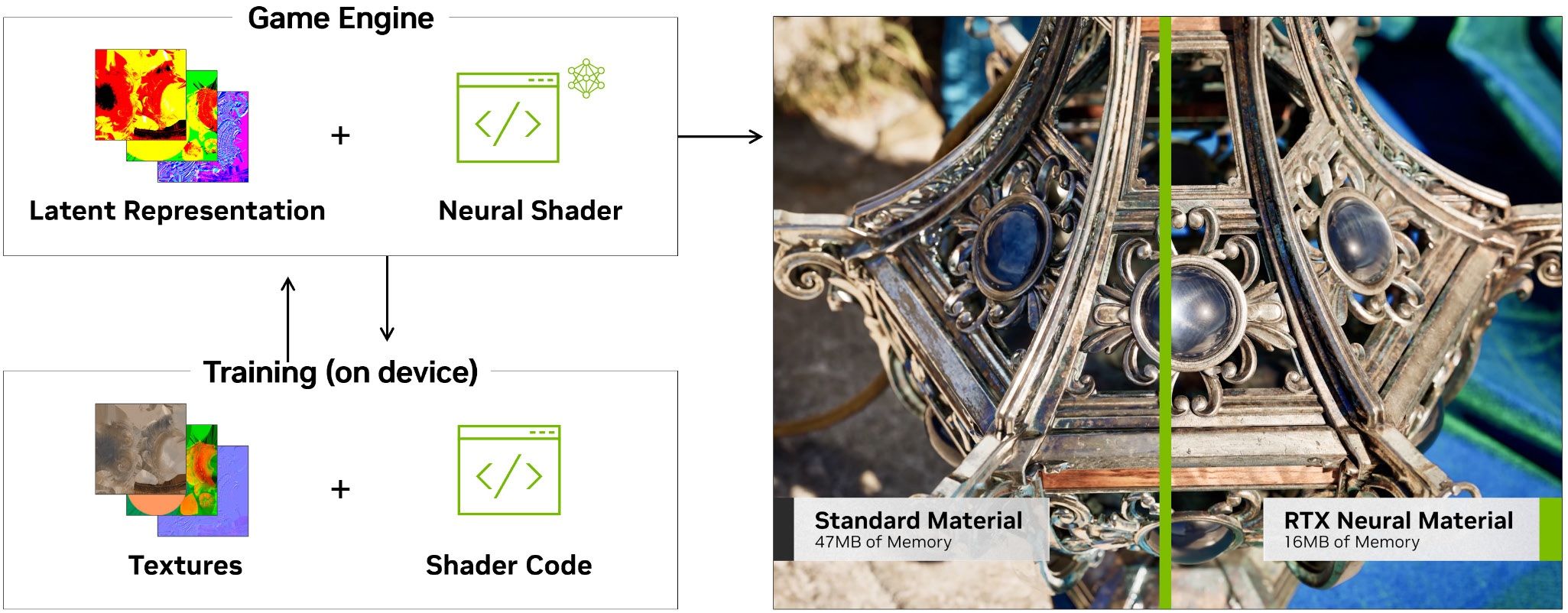
Перший напрямок зрозумілий із назви – стискання текстур. Завдяки нейромережам обсяг споживання VRAM можна скоротити до 7 разів, зберігаючи співставну якість.

Другий — обробка складних багатошарових матеріалів, таких як порцеляна чи шовк. У цьому напрямку очікується прискорення до 5 разів.

Третій же пов’язаний з освітленням. За допомогою тренування нейромережі у реальному часі, створюється і відправляється в кеш приблизна модель непрямих або вторинних відображень променів. Це значно спрощує та пришвидшує процес трасування, адже RT-ядрам потрібно прораховувати лише первинні відображення.
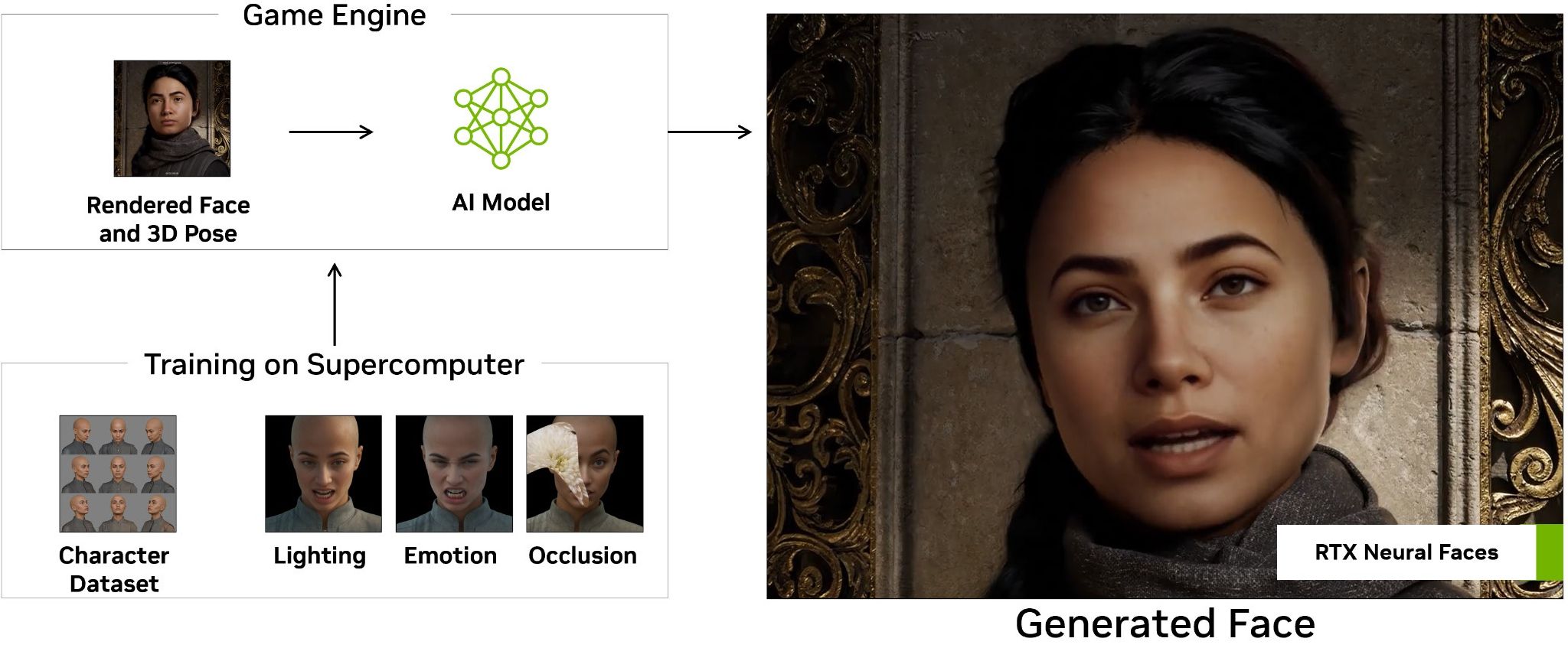
Окремо варто згадати механізм створення облич, який зазвичай потребує значних ресурсів GPU. Вгадайте на чому він тепер буде опрацьовуватись? Правильно, на нейромережах. Береться растрове зображення обличчя та його 3D-координати у певному кадрі і далі усе це міксується та оптимізується із безліччю заздалегідь згенерованих варіантів освітлення, емоцій, профілів чи інших об’єктів, з якими це обличчя може взаємодіяти.
Якщо ще не втомилися від теорії, переходимо до більш прикладних речей — безпосередньо до відеокарти.

Вивчати можливості лінійки Blackwell почнемо із предтопової моделі, яка опинилась у нас на руках – Palit GeForce RTX 5080 GameRock.

Якщо розглядати чип RTX 5080 (він же GB203) та підсистему пам’яті, то за кількістю обчислювальних блоків і мікросхем VRAM це, по суті, половина RTX 5090. GPU містить 10752 CUDA-ядра, по 336 текстурних конвеєрів та тензорних ядер, а також має 112 ROP-блоків і 84 RT-ядра. Робоча частота у базовому режимі становить 2295 МГц, а у бустовому - до 2617 МГц. Кеш першого рівня – по 128 КБ на кожний SM, а загальнодоступний L2 вміщує до 64 МБ даних. Шина GDDR7-пам’яті 256-бітна із ефективною частотою у 30 гігабіт на секунду та загальною пропускною здатністю у майже 1 ТБ. Загальний обсяг VRAM – 16 ГБ. Теплопакет пристрою теж вражає - його максимальну планку заявлено на рівні 360 Вт.


У конструктивному плані нам дістався ще той монстр. Довжина відеокарти становить майже 332 мм, а товщина займає 3,5 слоти. Є тут і цікава підсвітка, і круті «турбовентилятори» на подвійному кульковому підшипнику. Однак із більшою кількістю деталей радимо ознайомитись у окремому огляді.
Опоненти

Порівнювати новинку будемо насамперед з попередницею – Palit GeForce RTX 4080 SUPER JetStream OC.

Шейдерних обчислювачів у неї трохи менше – 9728, та й за іншими характеристикам вона майже не поступається - текстурників та тензорних ядер по 304, блоків растеризації так само 112, а RT-ядер - 76. Кеш L2 між поколіннями не змінився - 64 МБ, як і шина пам’яті та обсяг VRAM – 256 біт та 16 ГБ відповідно. Проте сама пам’ять стандарту GDDR6X повільніша і здатна пропускати лише близько 720 ГБ за секунду. TDP карти - 320 Вт.

Далі дізнаємося як героїня огляду виглядає на фоні прискореної Palit GeForce RTX 4080 SUPER JetStream OC. Чи буде між картами якась різниця? Адже із цією суперницею гандикап по виконавчим блокам ще менший.

Також розглянемо топ 40-ї лінійки - Palit GeForce RTX 4090 GameRock OC. Це протистояння теж варте уваги, адже, наприклад, RTX 4080 свого часу впевнено випередила не лише RTX 3090, а й її Ti-версію.

І на солоденьке у нас лишається ASUS TUF Gaming Radeon RX 7900 XTX OC Edition, безкомпромісне рішення з протилежного табору. Якщо не враховувати рейтрейсинг, то для RTX 4080 та її SUPER-версії це серйозний суперник у погоні за вищім FPS.
Тестовий стенд

Якраз до тестування відеокарт нам вдалося оновити тестовий стенд, щоб він краще відповідав максимальним вимогам сучасних ігор.

В його основі тепер працює 8-ядерний 16-потоковий ігровий процесор Ryzen 7 9800X3D під сокет AM5. Робочі частоти «новинки» варіюються від 4,7 до 5,2 ГГц, а L3-кеш сягає аж 96 МБ. У найближчих оглядах ми неодмінно доберемось і до його порівняння, тож слідкуйте, не пропустіть!

Повертаємось до тестового стенду. Для нового процесора обрали топову та актуальну материнську плату - ASUS ROG STRIX X870E-E GAMING WIFI.

Охолоджувався процесор 360-мм РСО ASUS TUF Gaming LC II 360 ARGB.

Для зберігання тимчасових даних використовували двомодульний комплект Kingston FURY Renegade RGB DDR5-6400 обсягом 32 ГБ із таймінгами 32-39-39 і напругою 1,4 В. Виглядає ОЗП стильно, а 12-точкова RGB-підсвітка додає ще більше ефектності.

Операційну систему і допоміжний софт зберігали на оптимальному за співвідношенням ціна/можливості M.2 PCI-E 4.0 x4 накопичувачі Kingston KC3000 на 1 ТБ. Він забезпечує до 7000 МБ/с при зчитуванні та 6000 МБ/с при записі, а продуктивність на довільних 4K-блоках сягає 1 мільйона IOPS. Підібрати оперативну пам'ять або SSD-накопичувач Kingston можна на сайті kingston.com, де є зручний інструмент для підбору оперативної пам’яті - достатньо ввести назву материнської плати або ноутбука, і система підбере сумісні комплектуючі.

Живився стенд від кіловатного Seasonic VERTEX GX-1000 із сертифікатом 80 Plus Gold, що гарантує високу енергоефективність.

І у єдину цілісну конструкцію всі комплектуючі об’єднав корпус ASUS TUF Gaming GT302 ARGB, який оснащується чотирма додатковими вентиляторами.
Прогрів
Новенька відеокарта, вражаючий TDP. Тож цікаво, як вона охолоджується та наскільки ефективно?
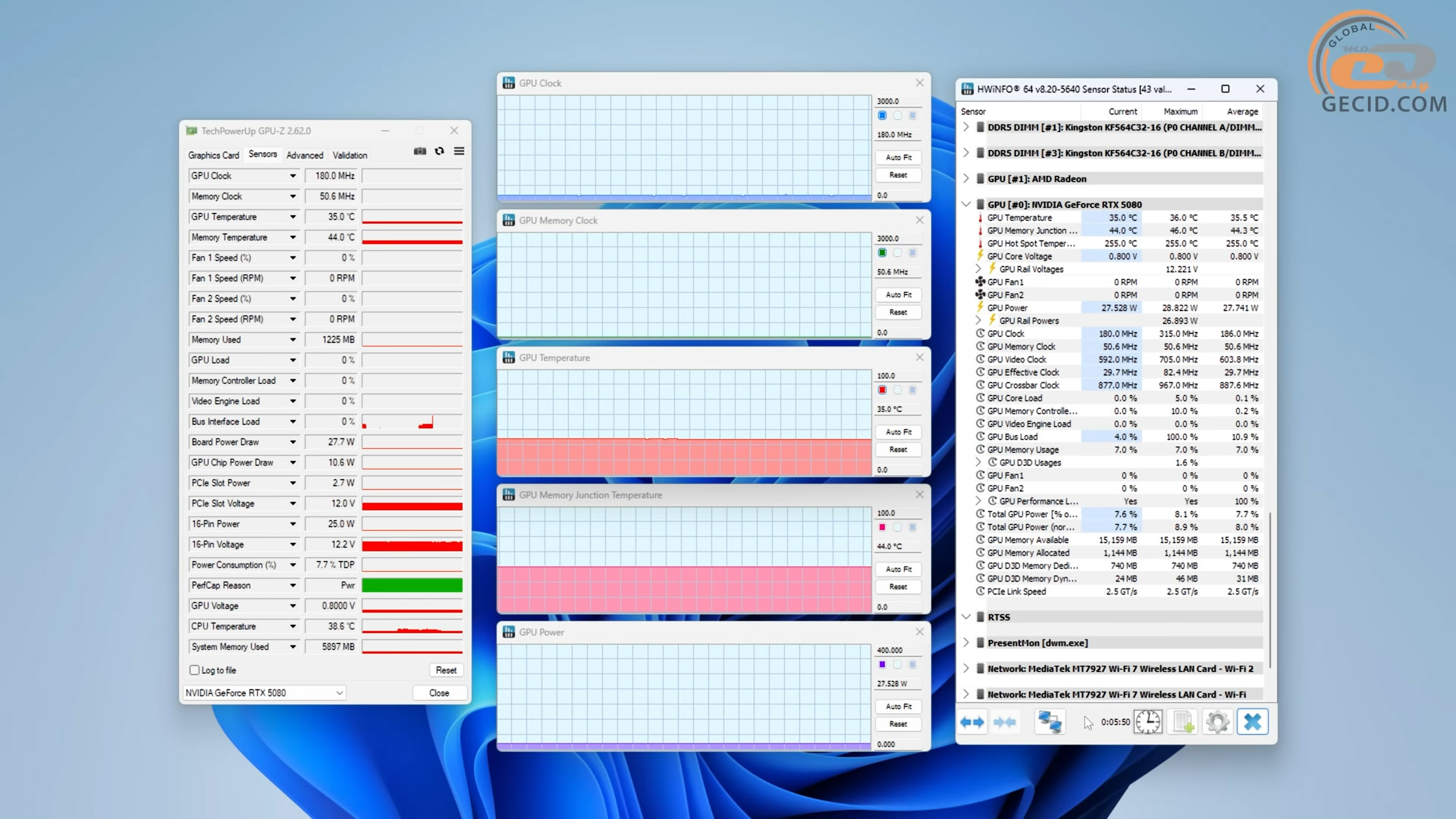
Без 3D-навантаження температура GPU при пасивному режимі вентиляторів склала скромні 35 градусів. Споживання не перевищувало 30 Вт. Нічого надзвичайного.
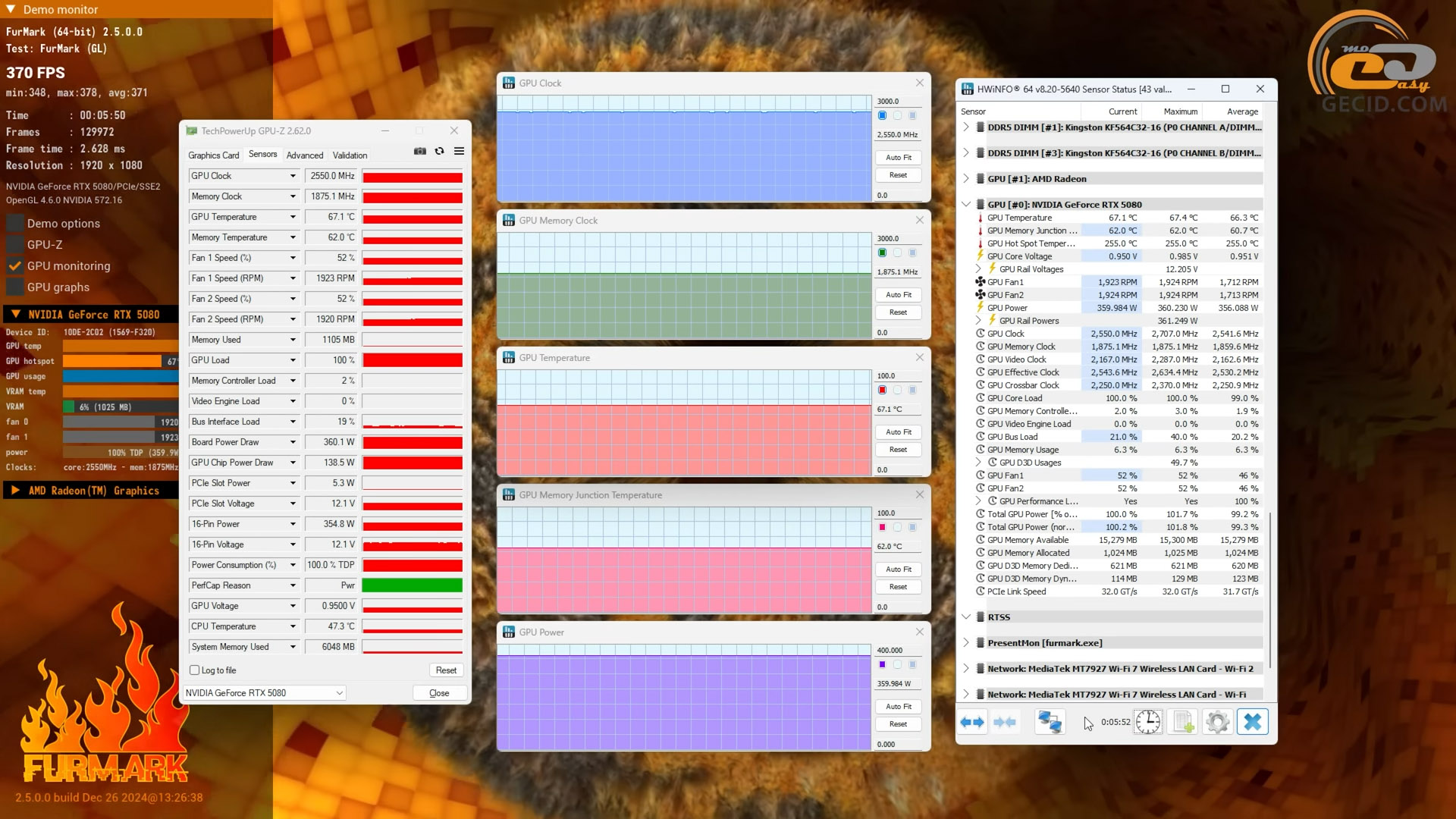
Під стресом у FurMark, як не дивно, теж усе добре – 67 градусів на чипі, 62 на VRAM, і це при реальних 360 ватах споживання. Масивна система охолодження працює бездоганно.
Синтетика
Перш ніж переходити до синтетичних тестів, одне уточнення. Оскільки RTX 5080, м’яко кажучи, продукт новий, у бенчмарках виникли деякі проблеми. Наприклад, Cinebench 2024 взагалі не зміг розпізнати відеокарту.
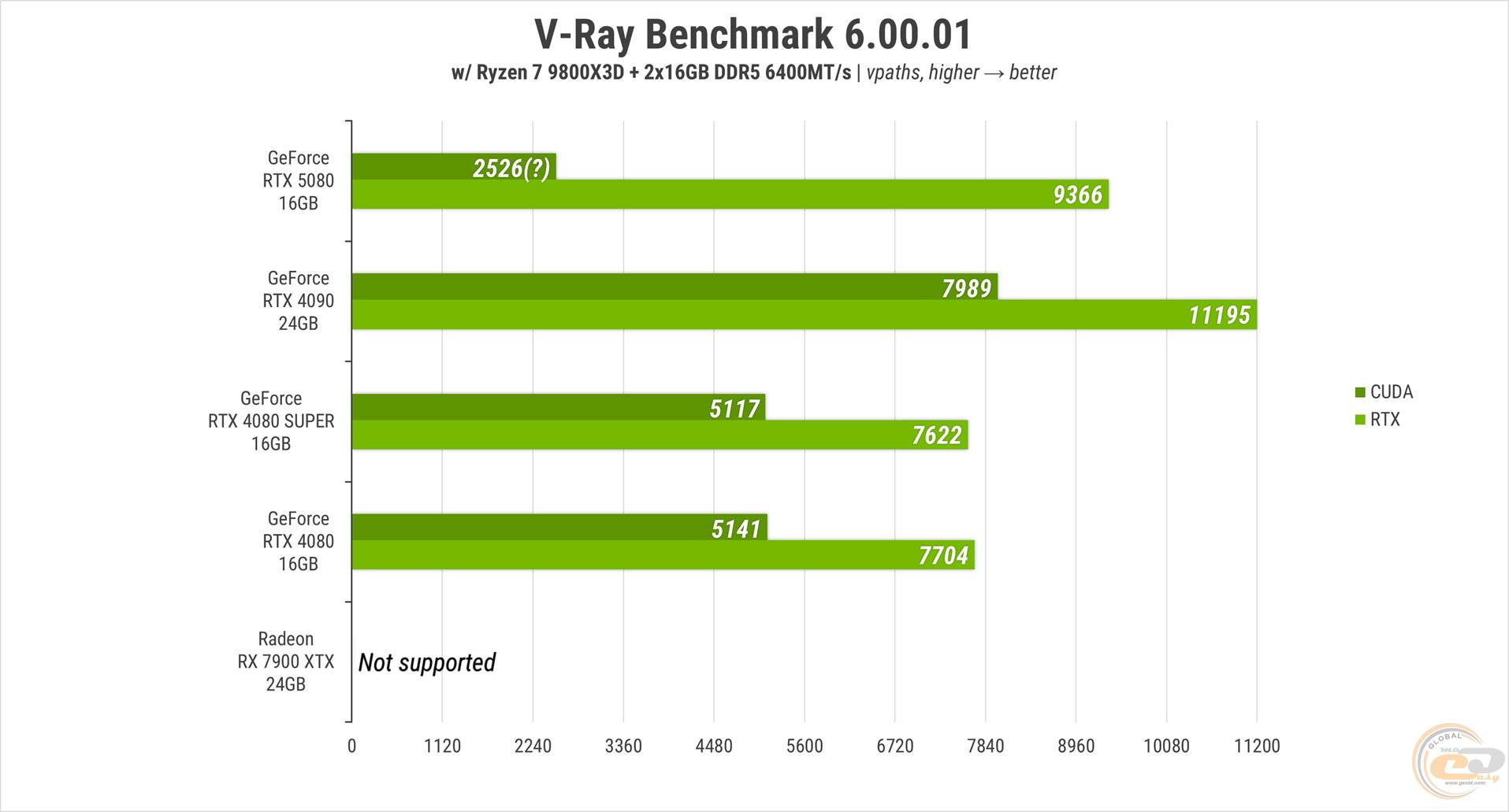
V-Ray Benchmark непогано оцінив продуктивність RT-ядер у піддослідної карти, але не зміг нормально завантажити шейдерні обчислювачі. Тому і результат такий аномально низький.
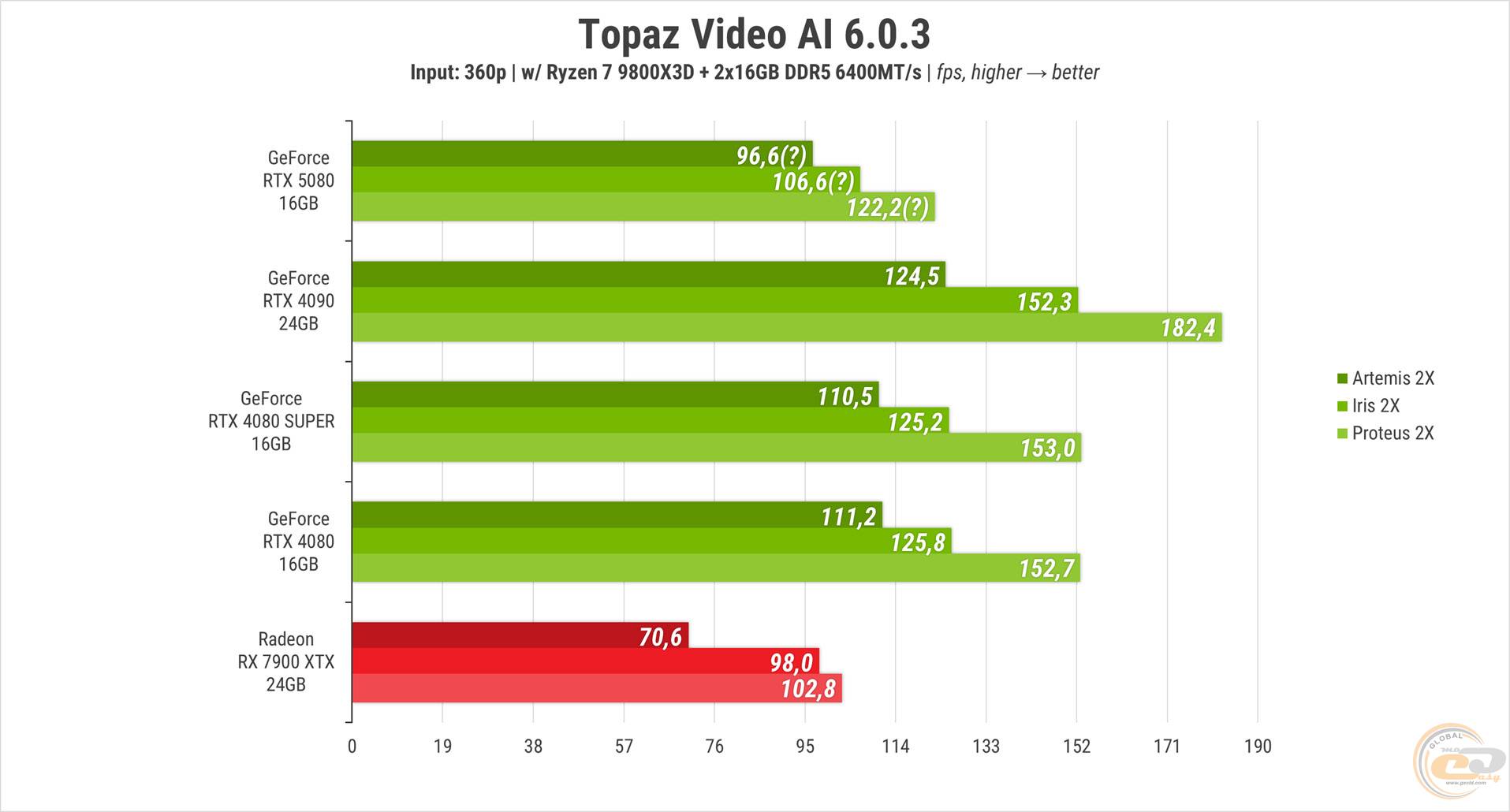
До цього хаосу долучився й Topaz Video AI, продемонструвавши підозріло низьку продуктивність новинки.
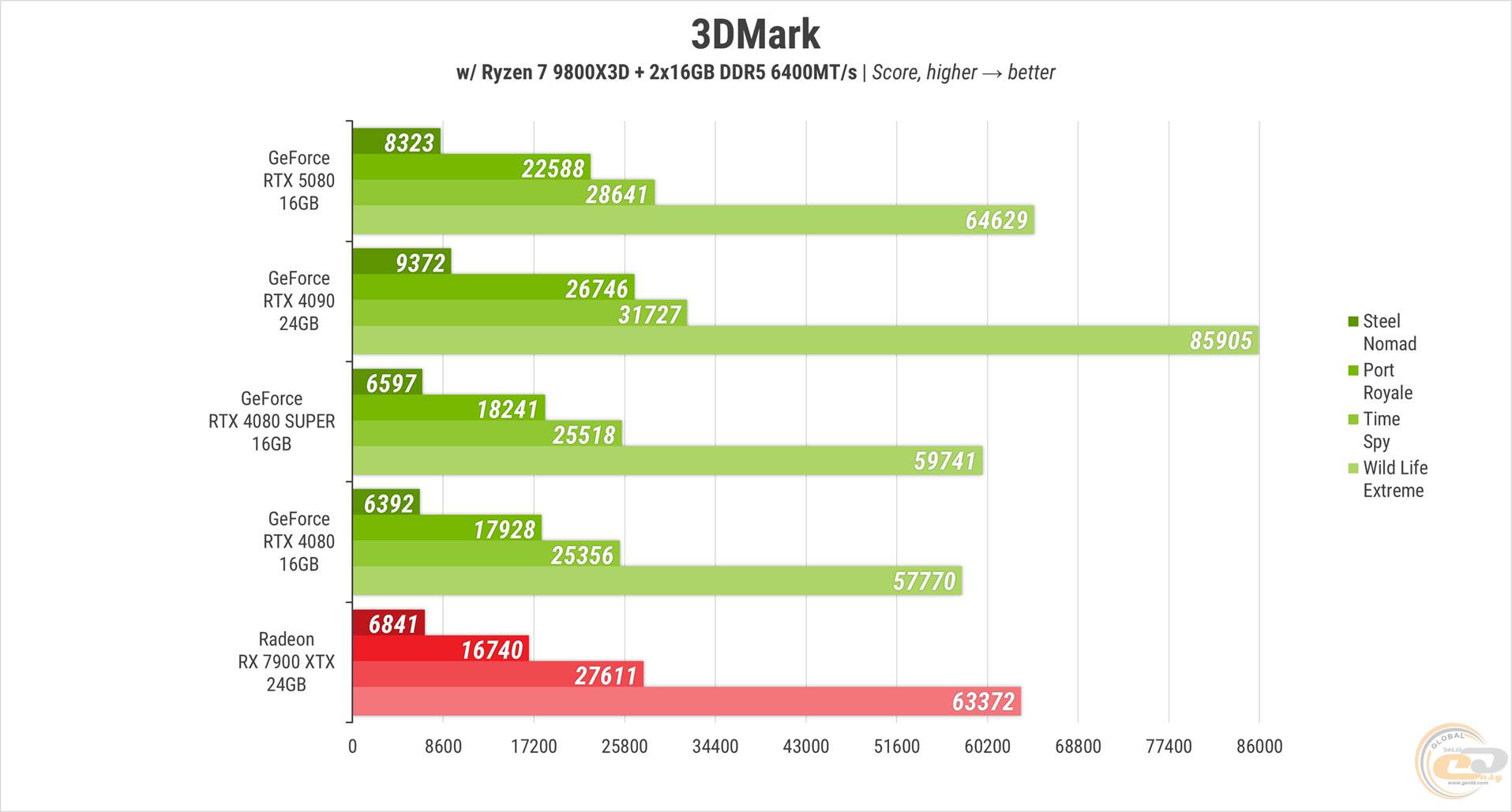
У 3DMark «папужки» виглядали вже більш-менш охайно, яскраво і логічно. Героїня огляду випереджає RTX 4080 на величину до 30%, її SUPER-версію - до 26%, а RX 7900 XTX - до 35%. Водночас вже-не-топу NVIDIA вона серйозно програє - до 25%.
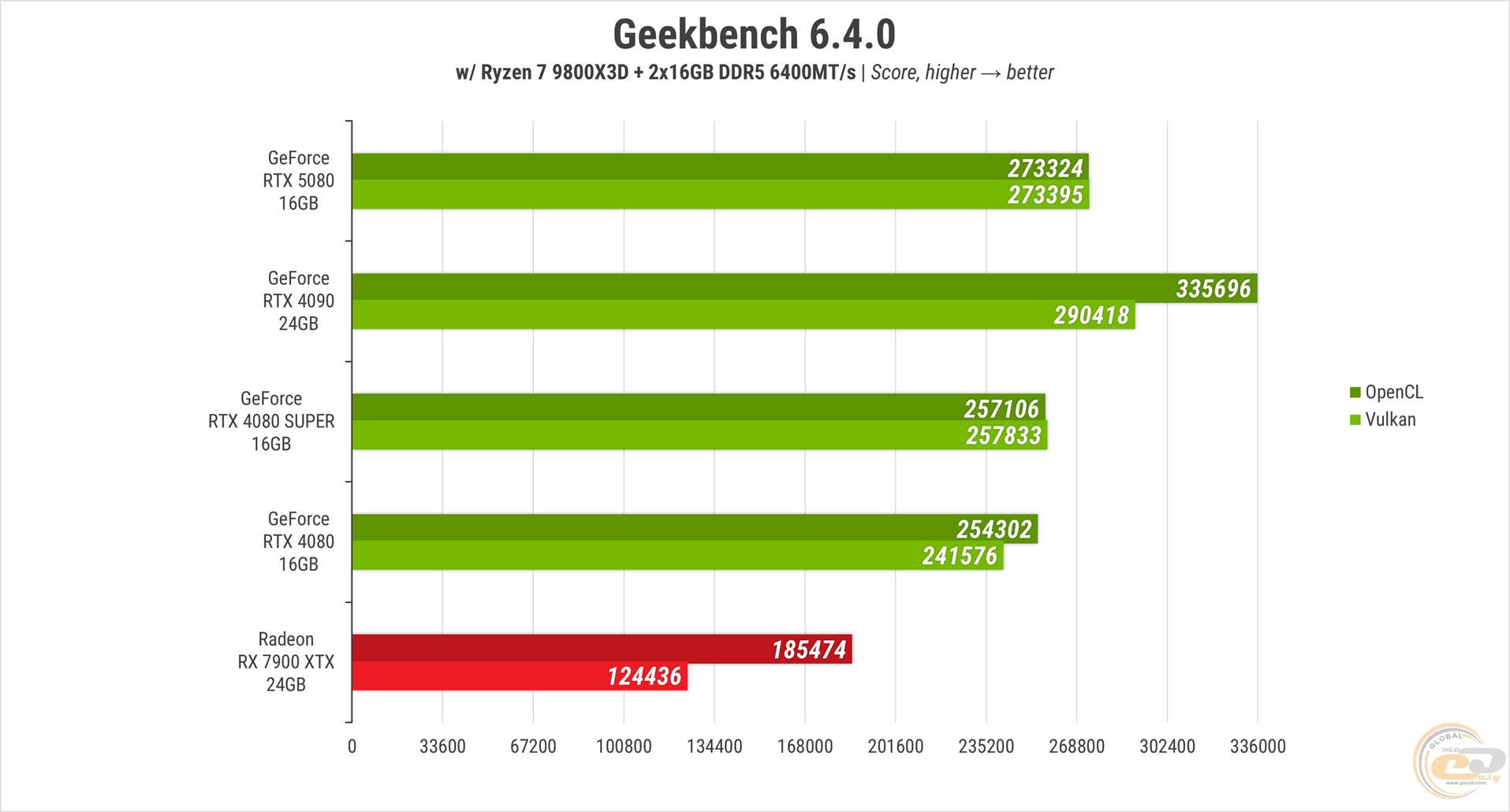
Geekbench 6, схоже, зміг адекватно оцінити можливості відеокарти. Свою попередницю RTX 5080 випереджає на 7-13% залежно від API, на 6% обходить RTX 4080 SUPER і значно випереджає RX 7900 XTX – на 48-120%. Швидкодія RTX 4090 залишається недосяжною, вона демонструє на 6-23% кращі результати .
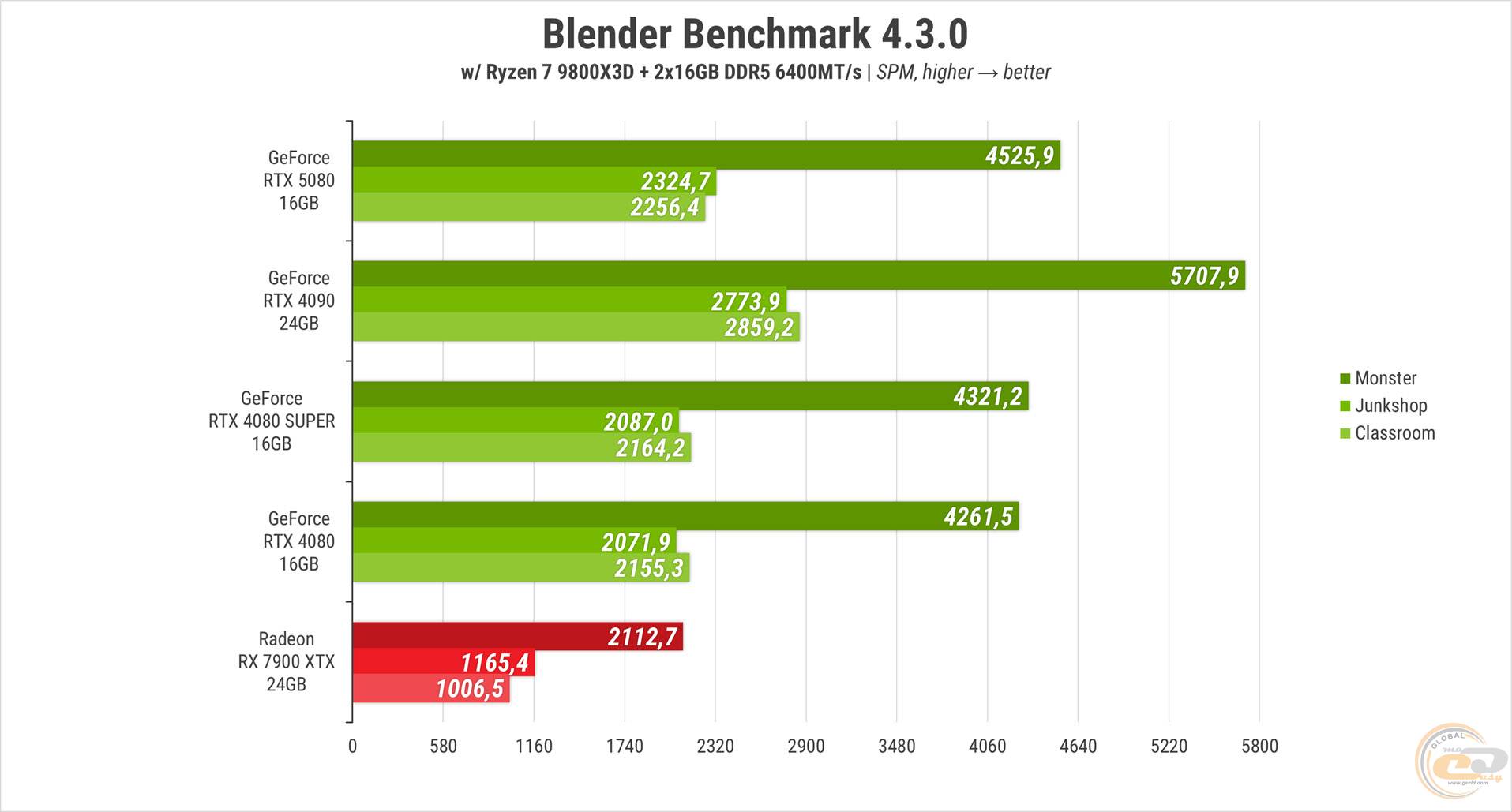
У Blender героїня огляду випередила обидві попередні 80-ки приблизно на 12%. Але знову поступилась топу зелених з минулого - на 16-21%. Карта червоних у даному змаганні не конкурент, її результати вдвічі менші за конкурентів.
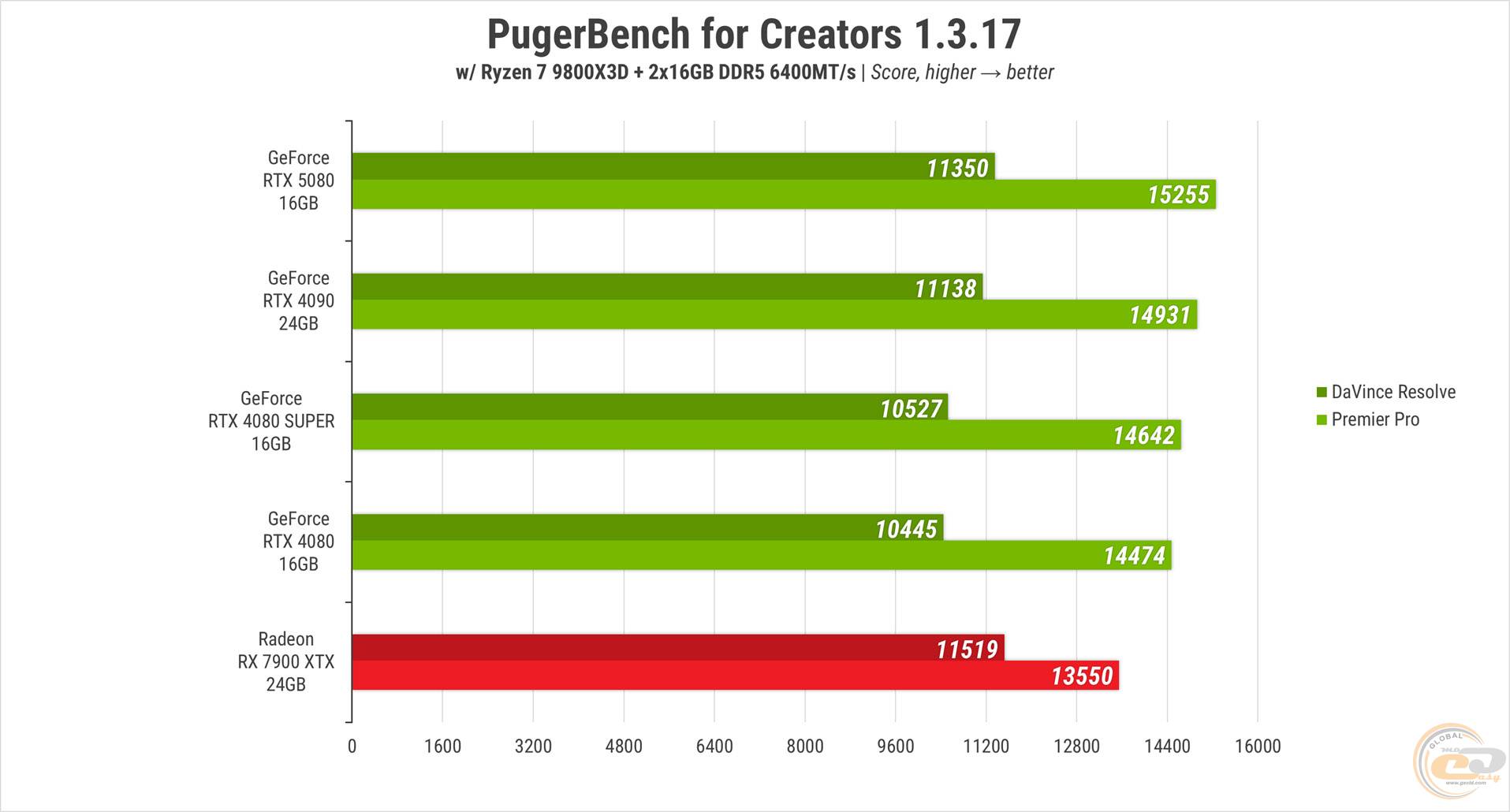
Бенчмарк професійного навантаження, Puget Bench for Creators, присудив RTX 5080 найвищу позицію серед карт NVIDIA. RTX 4090 відстала на кілька відсотків, а обидві RTX 4080 позаду на 4-8%. Прискорювач червоних у даному випадку – темна конячка, адже у одному з тестів навіть показав кращий результат.
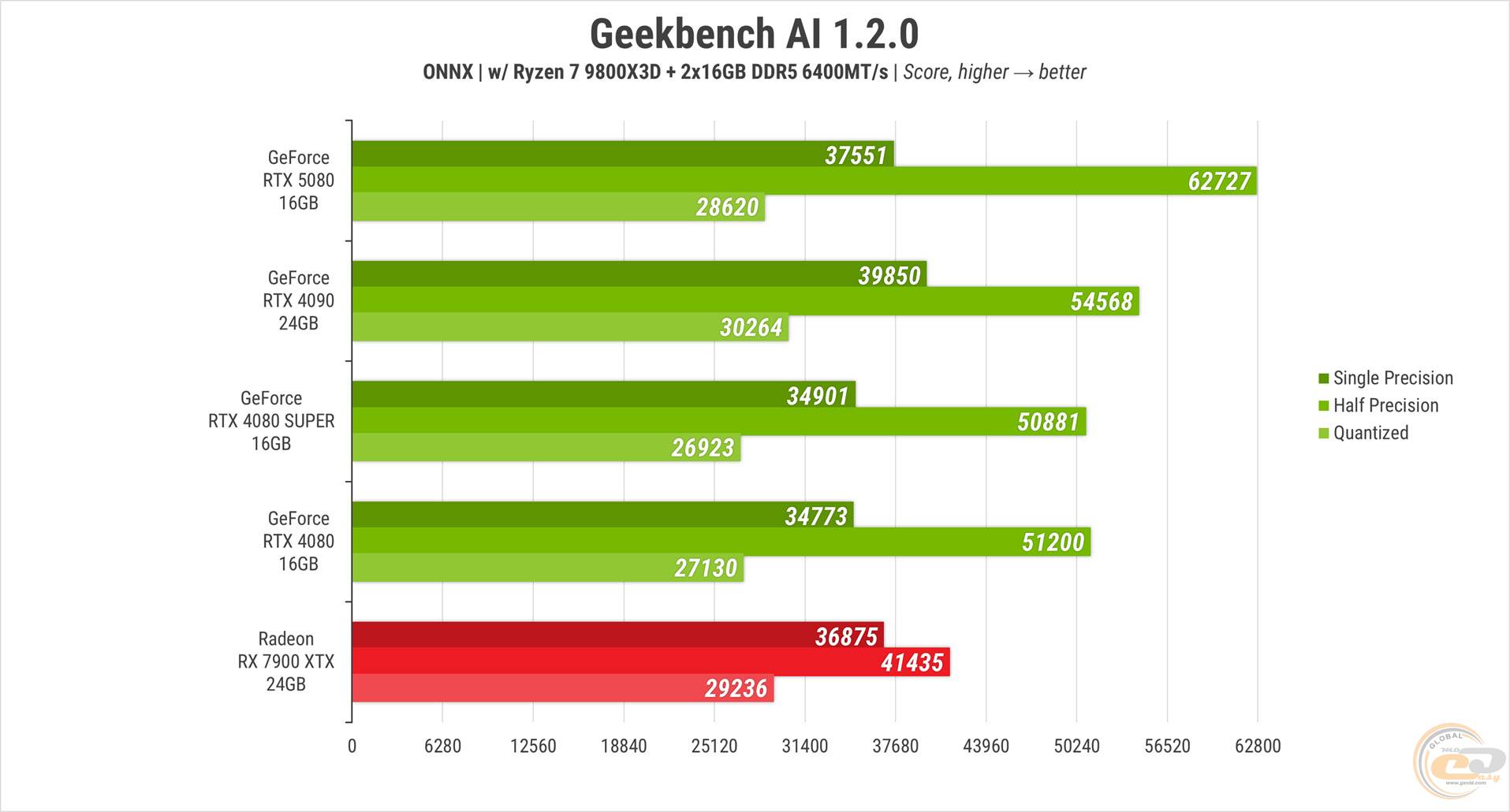
Також доволі упевнено RTX 5080 показала себе у Geekbench AI. І хоча RTX 4090 випередила її у двох із трьох типів розрахунків із перевагою у 6%, в режимі з половинною точністю обчислень новинка виявилася на 15% швидшою. Решта карт 40-ї серії, як і RX 7900 XTX, значно відстали.
Ігри
Наразі переходимо до ігор, які тестувалися виключно у 4K, адже саме на цю роздільну здатність орієнтована героїня огляду. Апскейлери та фрейм-генерацію не використовували, щоб оцінити саме приріст чистої продуктивності нового покоління.
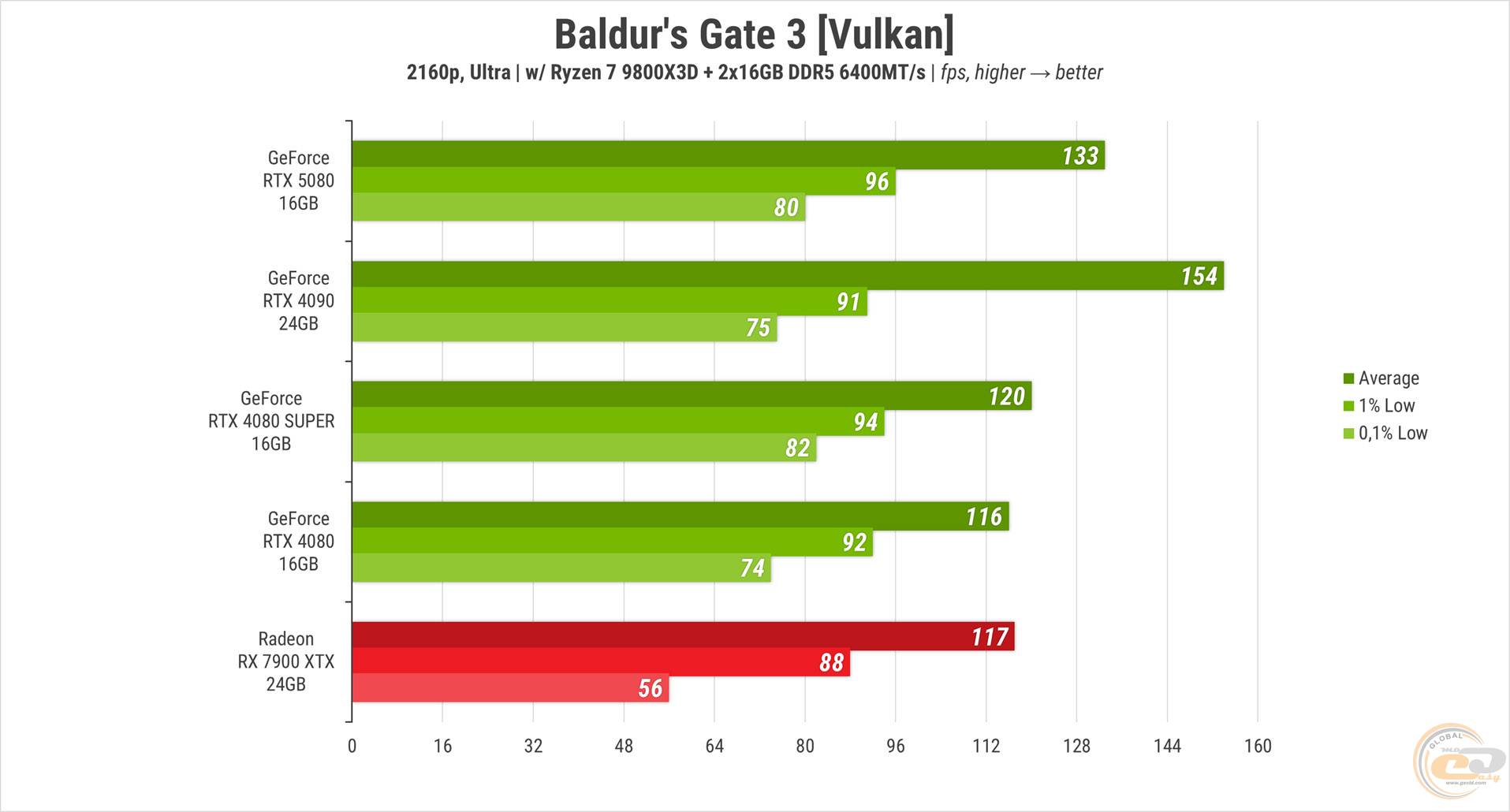
Пробіжка у Baldur’s Gate 3 проводилась на «ультра» пресеті в третьому акті. І перша ж гра показала, що порівнювати RTX 5080 із RTX 4090 за сирою продуктивністю, ймовірно, не варто. Старенька виявилась швидшою на майже 16% середньої частоти кадрів, хоча мінімальний FPS у неї був трохи нижчим. Відрив новинки від обох 80-к також не виглядає значним — 11% від SUPER-версії та майже 15% від звичайної. Результат червоної карти майже на рівні RTX 4080 SUPER.
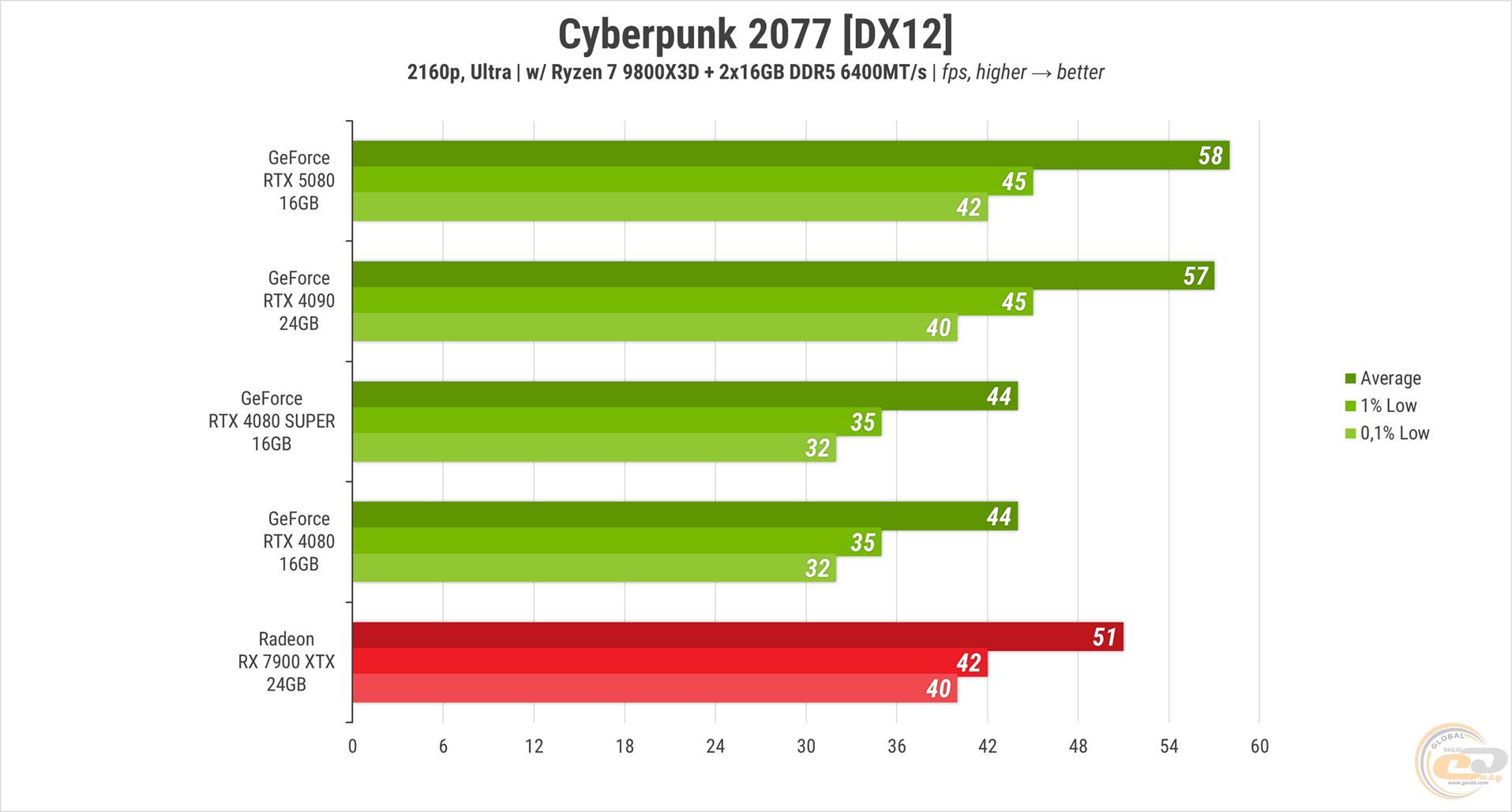
Промінь надії осяяв наші обличчя у Cyberpunk 2077 на максимальних налаштуваннях без RT. RTX 5080 несподівано зрівнялась з RTX 4090, навіть випередивши її на 1 FPS у середньому. Спочатку здалося, що впираємося у продуктивність процесора, але моніторинг і результати інших карт розвіяли це припущення. RX 7900 XTX опинилась позаду на 12%, а обидві RTX 4080 - на 24%.
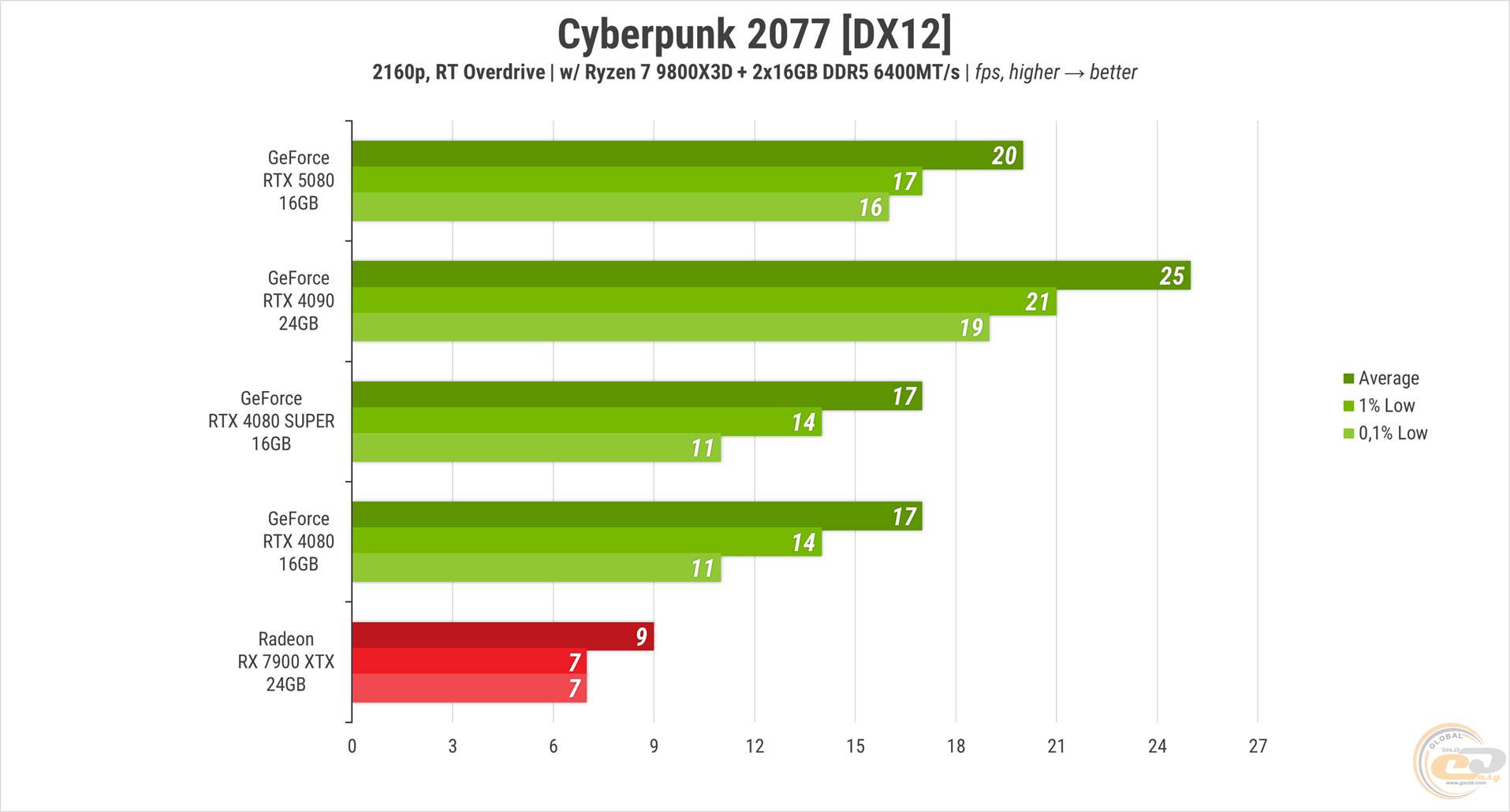
Вмикаємо «овердрайв», тобто трасування шляху, і отримуємо майже слайд-шоу на всіх відеокартах NVIDIA, а на RX 7900 XTX - беззаперечне. Лідером залишається RTX 4090 із на чверть вищим середнім лічильником.
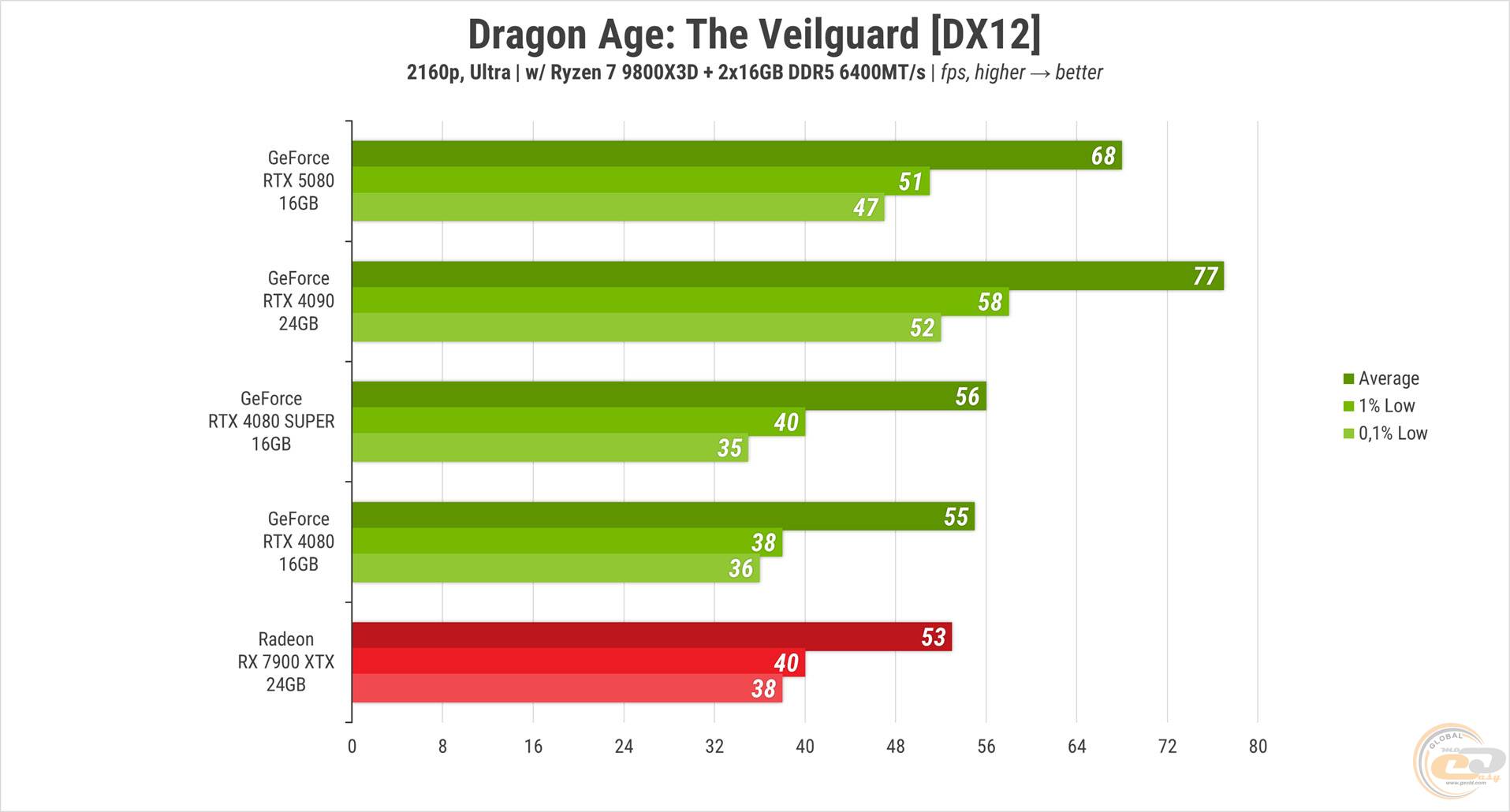
У Dragon Age: The Veilguard із «ультра» налаштуваннями RTX 5080 опинилася між топом 40-ї лінійки та всіма іншими учасницями, які показали майже однаковий FPS і не змогли подолати межу в 60 кадрів. Новинка ж перевершила цей показник на 8 FPS. Варто зазначити, що гра частково використовує трасування променів на цьому пресеті.
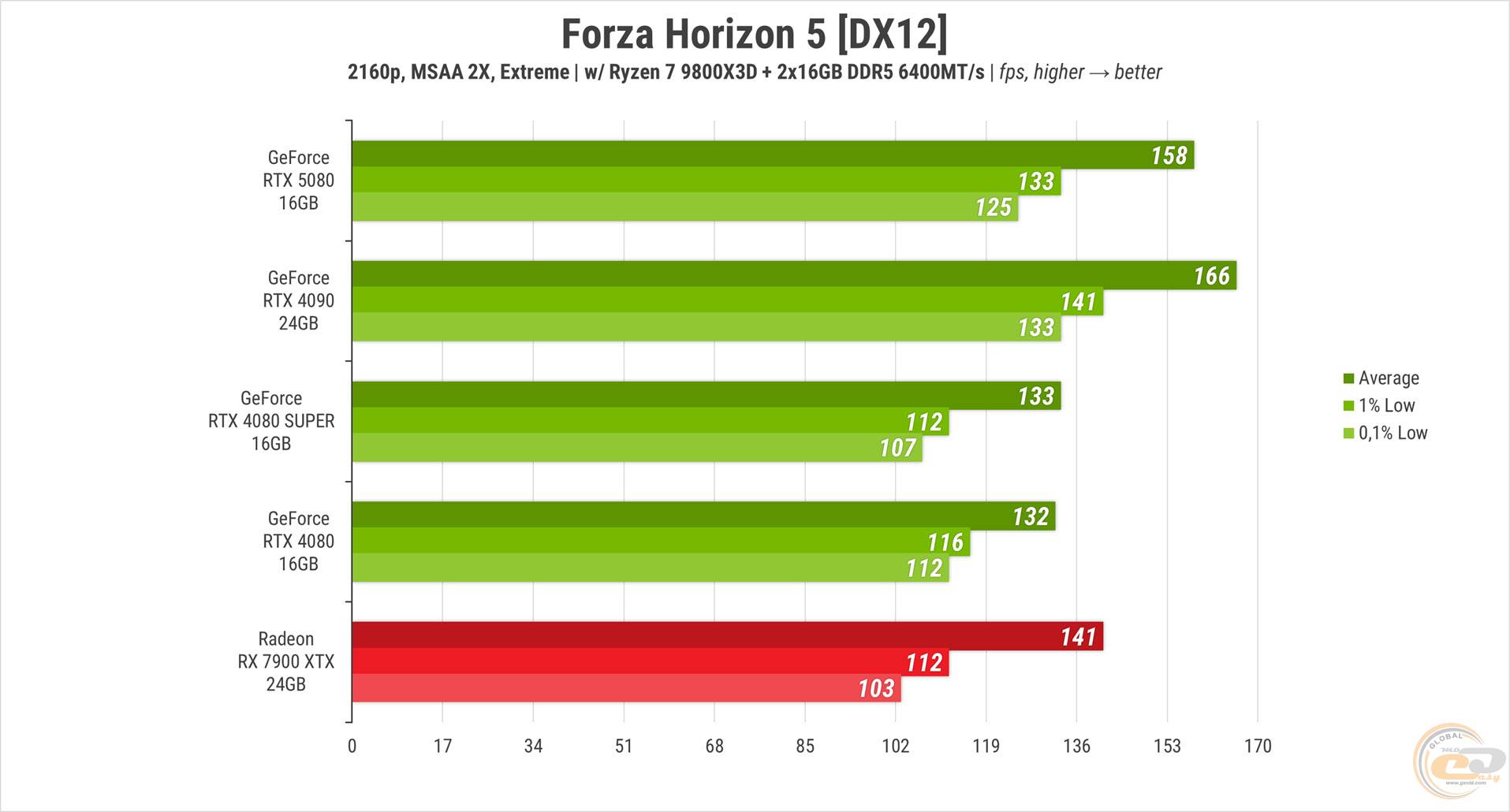
У Forza Horizon 5 піддослідній карті не вистачило всього 5% середнього FPS, щоб наздогнати RTX 4090. Водночас вона впевнено випередила RTX 4080 та її SUPER-версію на 20 та 19% відповідно. Червоній учасниці вдалося найближче підібратися до новинки, відставши на 11%.
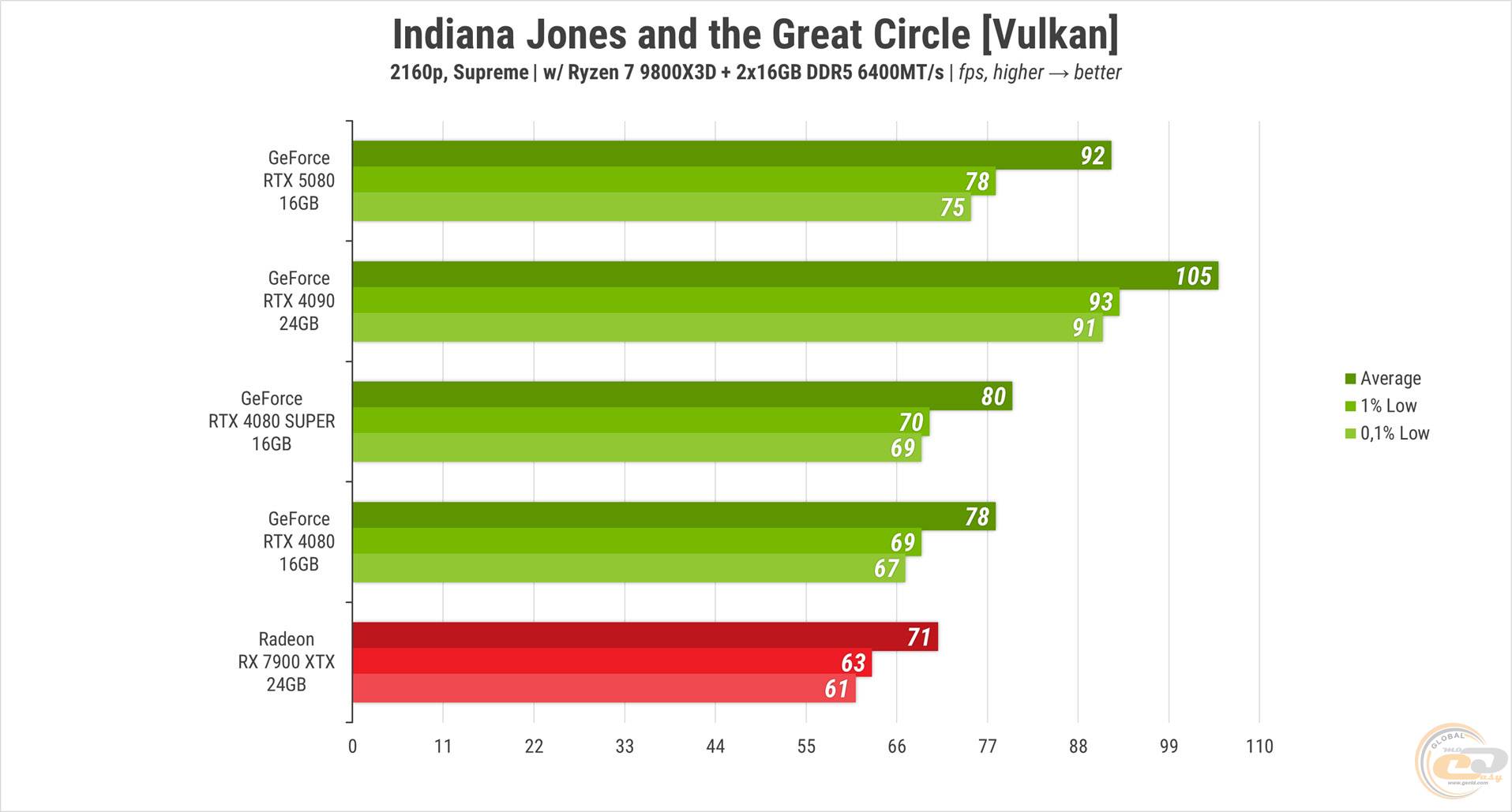
Indiana Jones and the Great Circle із пресетом «Supreme» лише закріпила тенденцію: RTX 5080 випереджає попередні 80-ки приблизно на стільки ж, на скільки відстає від топової моделі. Своєрідний «золотий середняк». RX 7900 XTX у цьому порівнянні опинилася ще на щабель нижче за обидві RTX 4080.
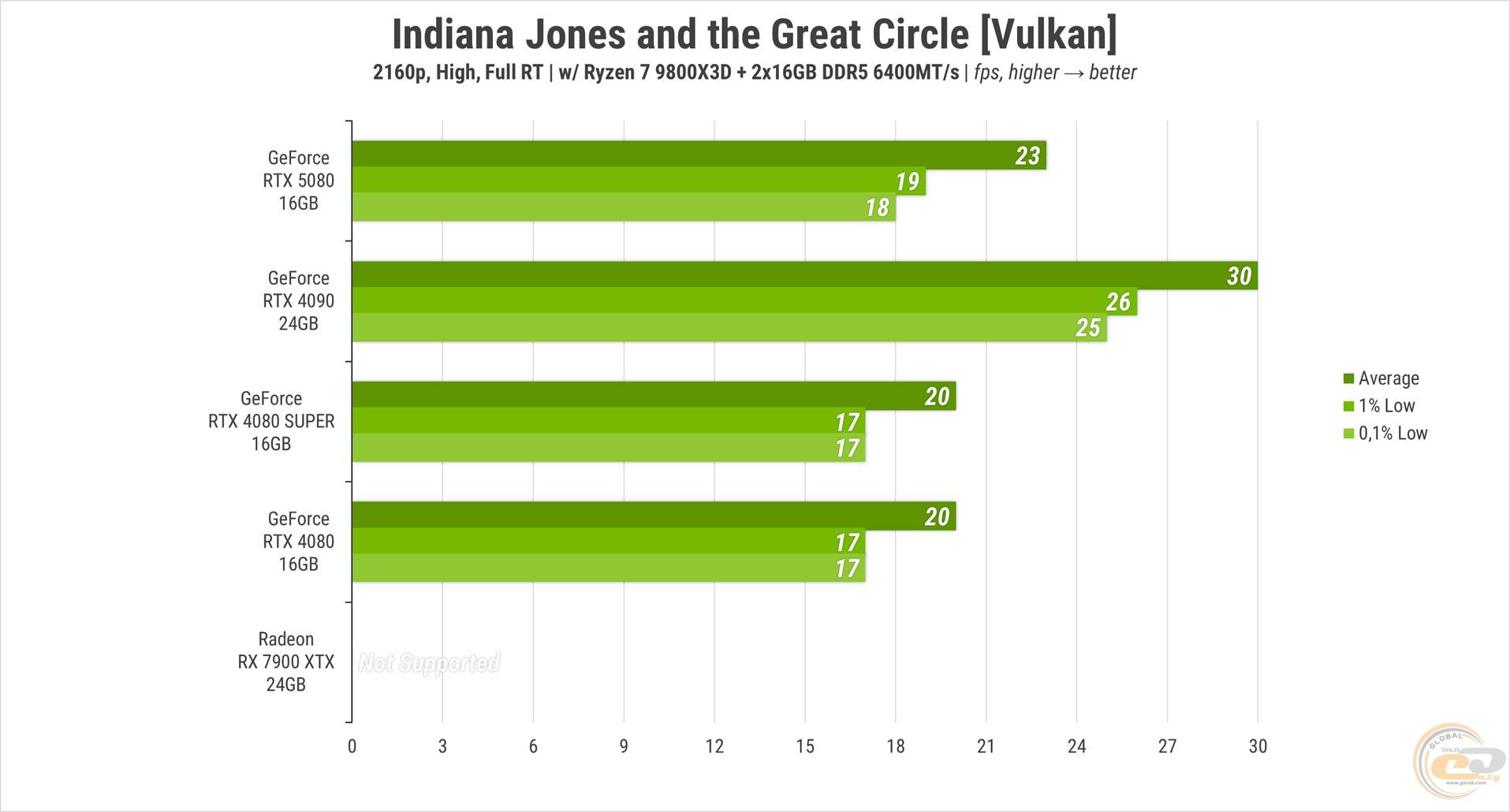
З увімкненим повним трасуванням променів гра стає непідйомною для всіх відеокарт, навіть на більш скромному «високому» пресеті. Якщо тільки ви не прихильник консольних 30 FPS — але навіть їх змогла витягнути лише RTX 4090. Червоний прискорювач взагалі залишається за бортом, оскільки гра не передбачає підтримки RT для нього.
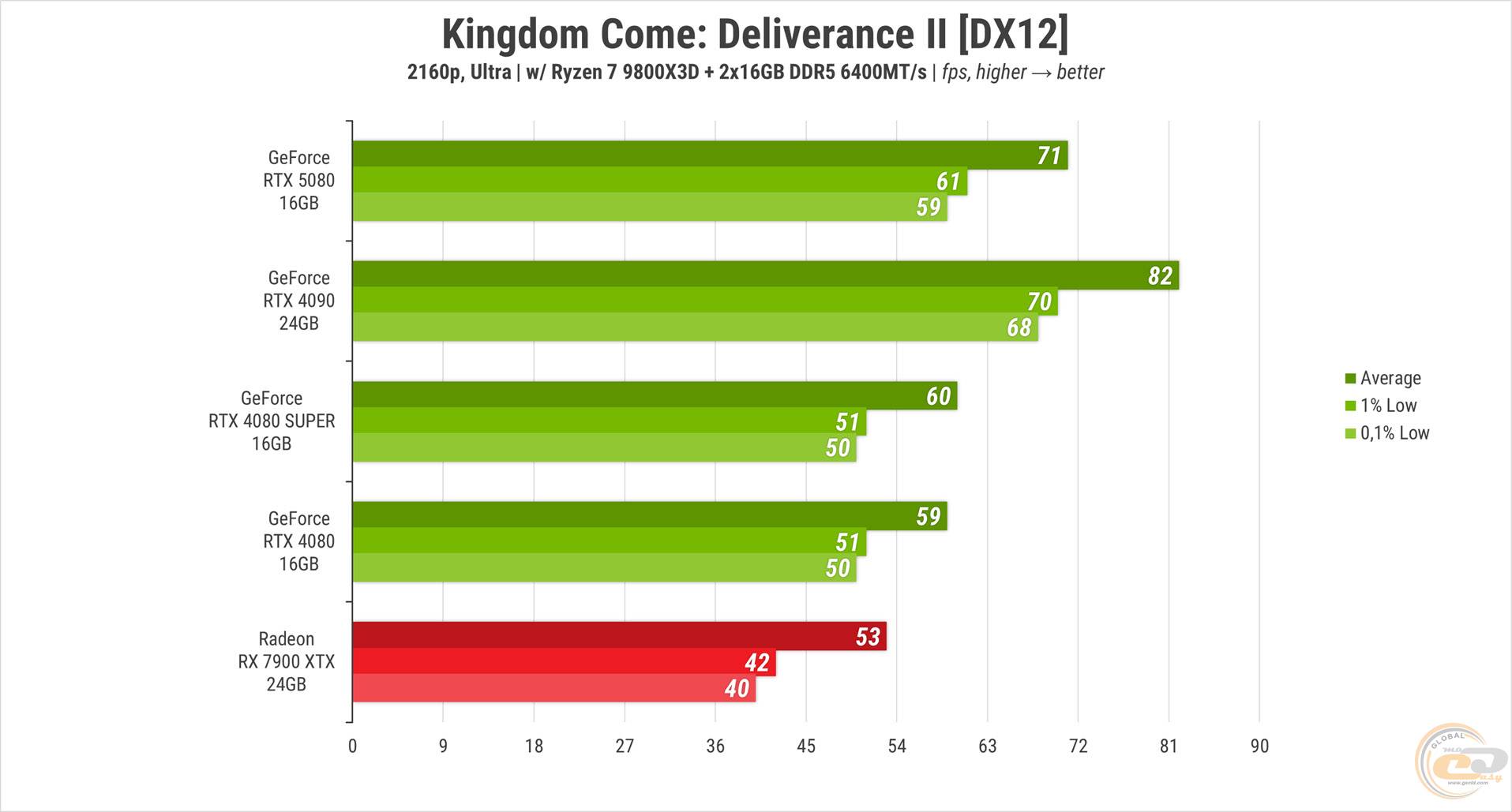
Із KingdomCome: Deliverance II на «ультрах», по суті, все теж саме. RTX 5080 оновлює зображення на 18-20% швидше ніж обидві попередниці, але на майже 16% повільніше за RTX 4090. RX 7900 XTX знову позаду - її середній FPS на 25% нижчий, і це єдина карта в тесті, яка не змогла забезпечити стабільні 60 кадрів на секунду.
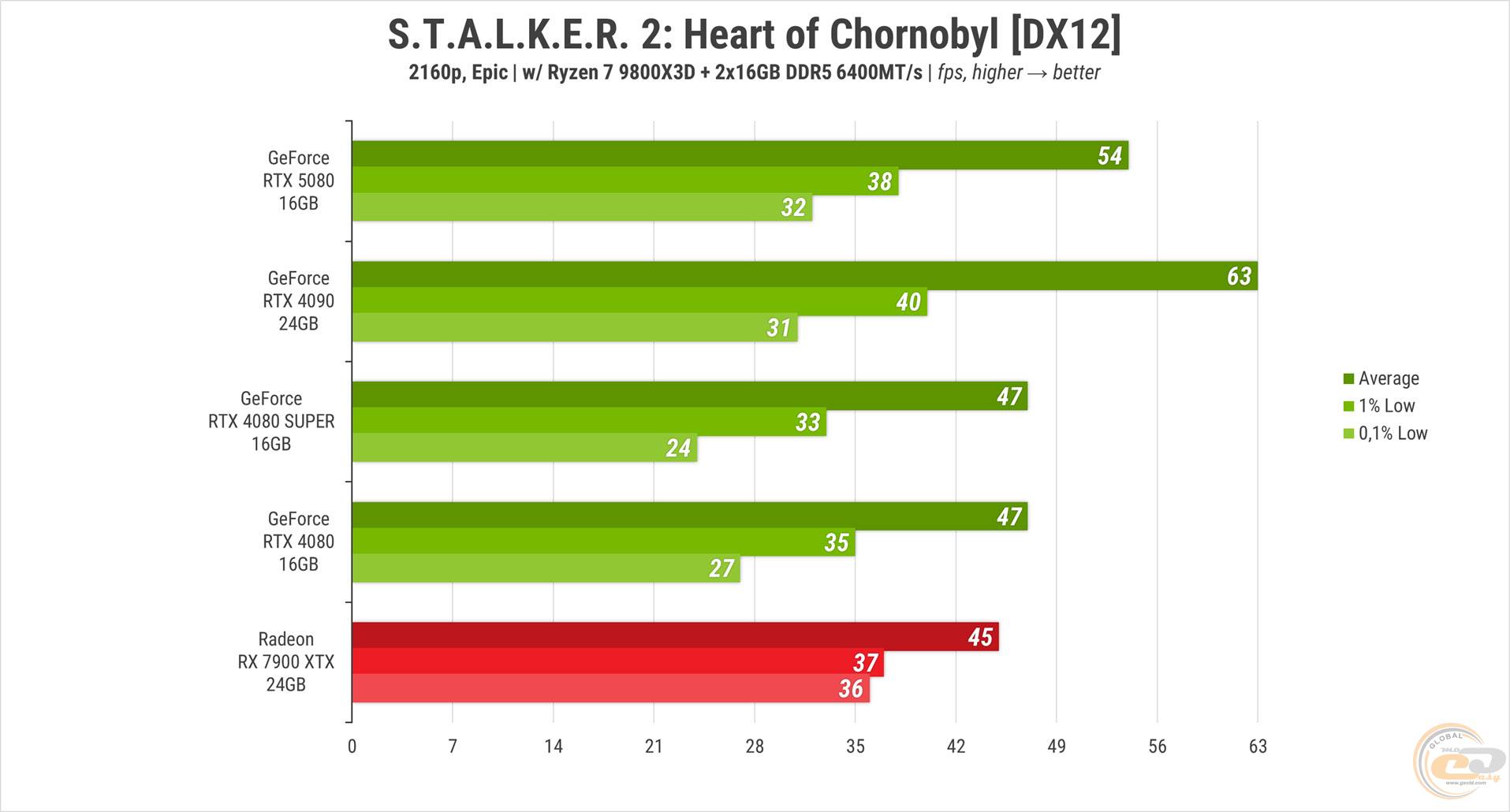
У другому «Сталкері» на «епічних» налаштуваннях помітно сильне просідання показника 0.1% Low у RTX 4080 та 4080 SUPER порівняно з іншими учасницями тесту. В іншому ж ситуація очікувана: RTX 5080 випереджає обидві 80-ки на 15%, а її на майже 17% випереджає RTX 4090. RX 7900 XTX в черговий раз на останньому місці, відстаючи від новинки на 17% за середньою частотою кадрів.
DLSS 4
Далі вирішили перевірити, як на практиці працює DLSS четвертої ревізії, і насамперед оцінити, чи покращила зміна моделі CNN на Transformer якість зображення при апскейлінгу.

Для цього запустили Cyberpunk 2077, обрали відповідну модель та перевели масштабування в «продуктивний» режим. І тут… навіть не знаємо, що сказати. Наче й є певні покращення то тут, то там, але в 4К та при динамічному геймплеї різниця майже непомітна. Тож, напевно, треба дивитися на більш статичні чи специфічні сценарії та при меншій роздільній здатності, що і спробуємо зробимо в одному з наступних оглядів.
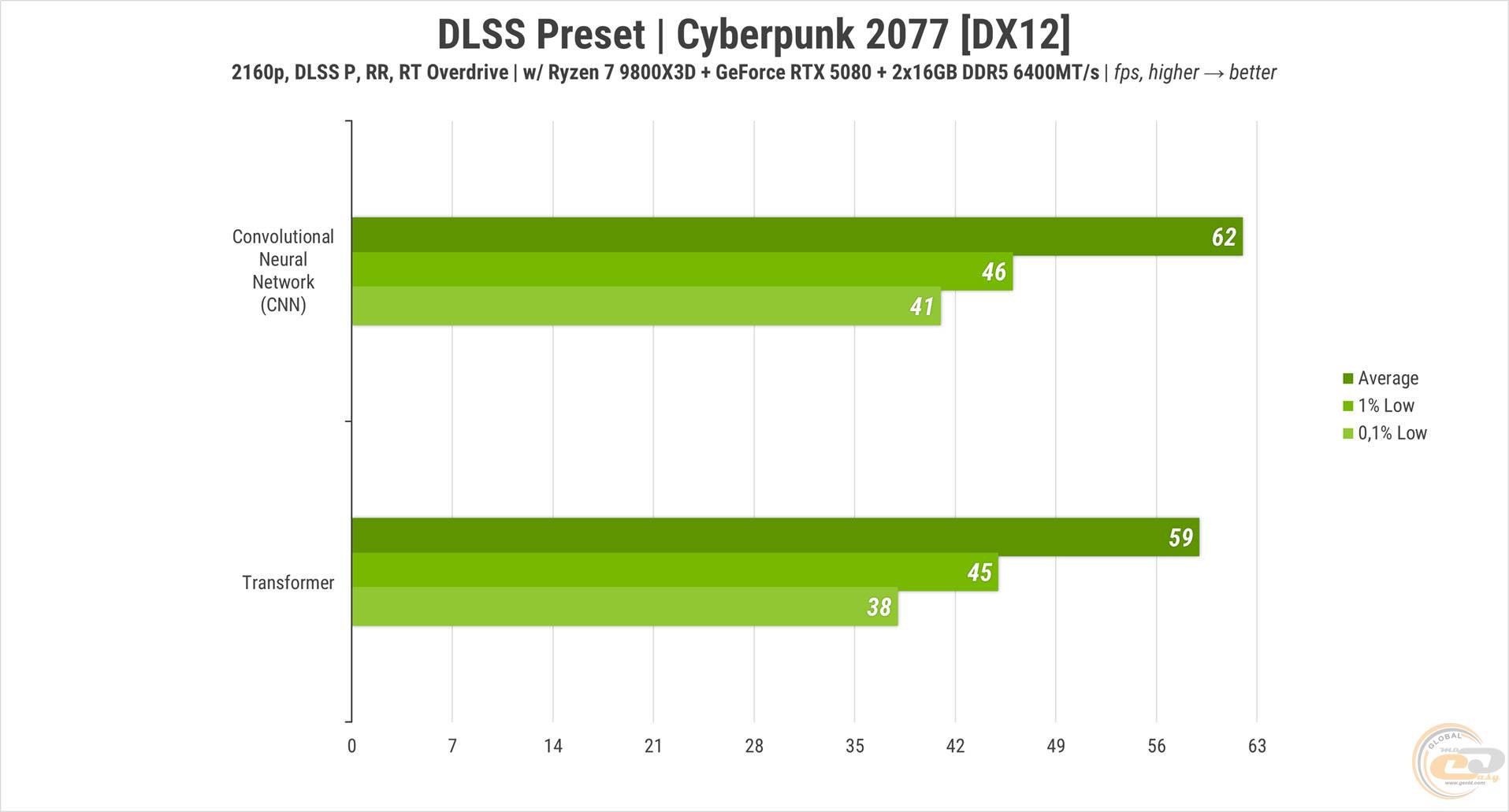
Але от що можемо підтвердити прямо зараз - продуктивність із новим підходом до аналізу зображення знизилася на 5%.
Продовжуємо тестування та подивимося на мультифрейм-генерацію.

Перший сценарій - той самий Cyberpunk 2077 із «продуктивно-трансформованим» DLSS, Ray Reconstruction та RT Overdrive. Без генератора кадрів на RTX 5080 гра видавала в середньому майже 60 FPS. Кожний наступний множник штучно згенерованих кадрів підвищував частоту приблизно на 70-75% від базового значення. У підсумку при x4 середній лічильник досягнув неймовірні 180 FPS з хвостиком, але без нюансів не обійшлося.
По-перше, інпут-лаг, особливо при генерації x4. Із «продуктивним» апскейлером він взагалі не відчувався. На «збалансованому» рівні — майже непомітний, а на «якісному» вже відчутний, але не критично. Найгірший досвід у цьому плані дає DLAA — з таким згладжуванням затримку в керуванні не помітити важко.
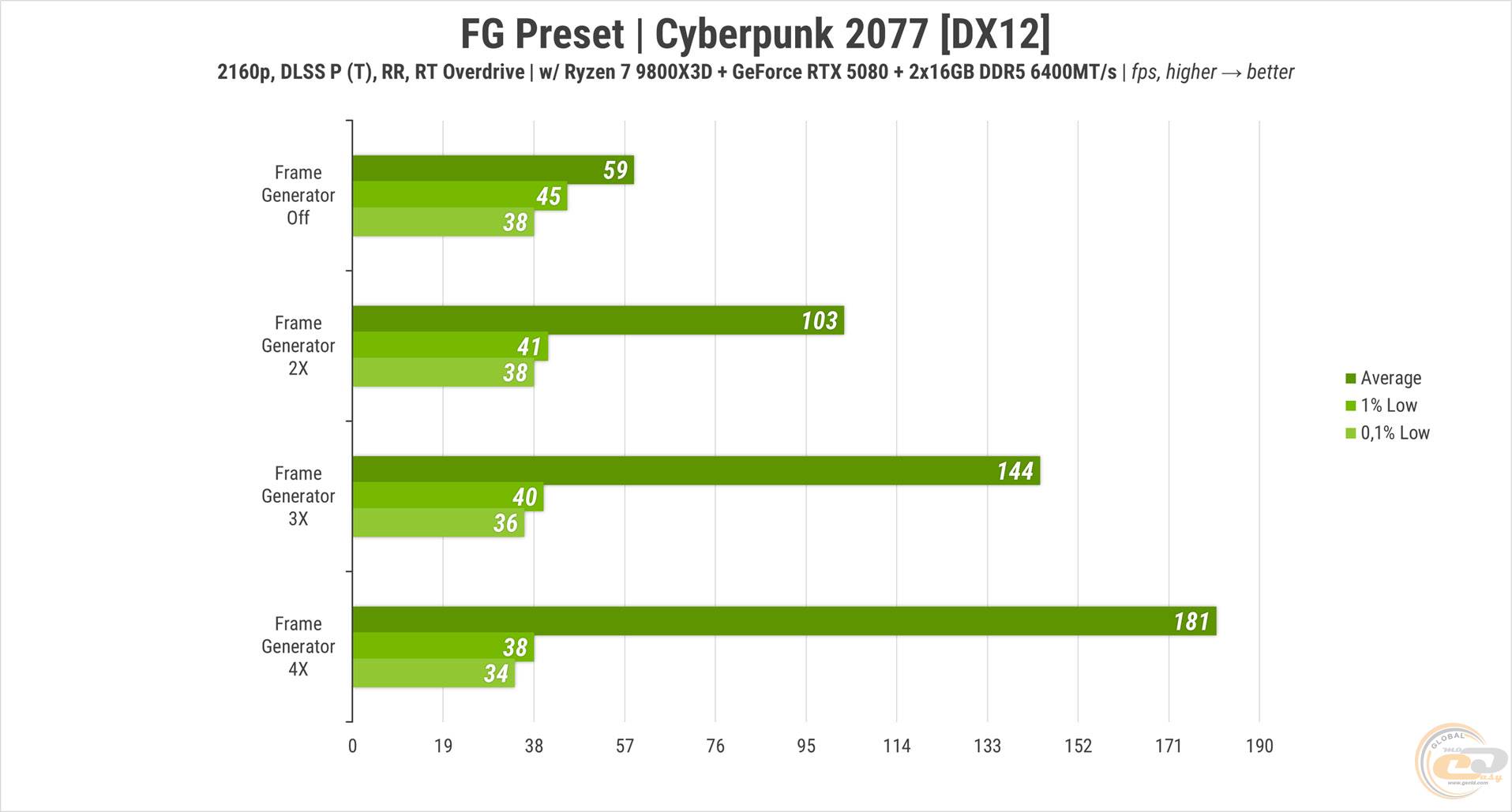
По-друге, показники 0,1 та 1% Low в даному випадку не відображають реальну статистику, а показують її для базової частоти. І, що цікаво, чим вищий множник фрейм-генерації, тим меншою на декілька кадрів стає базова частота.
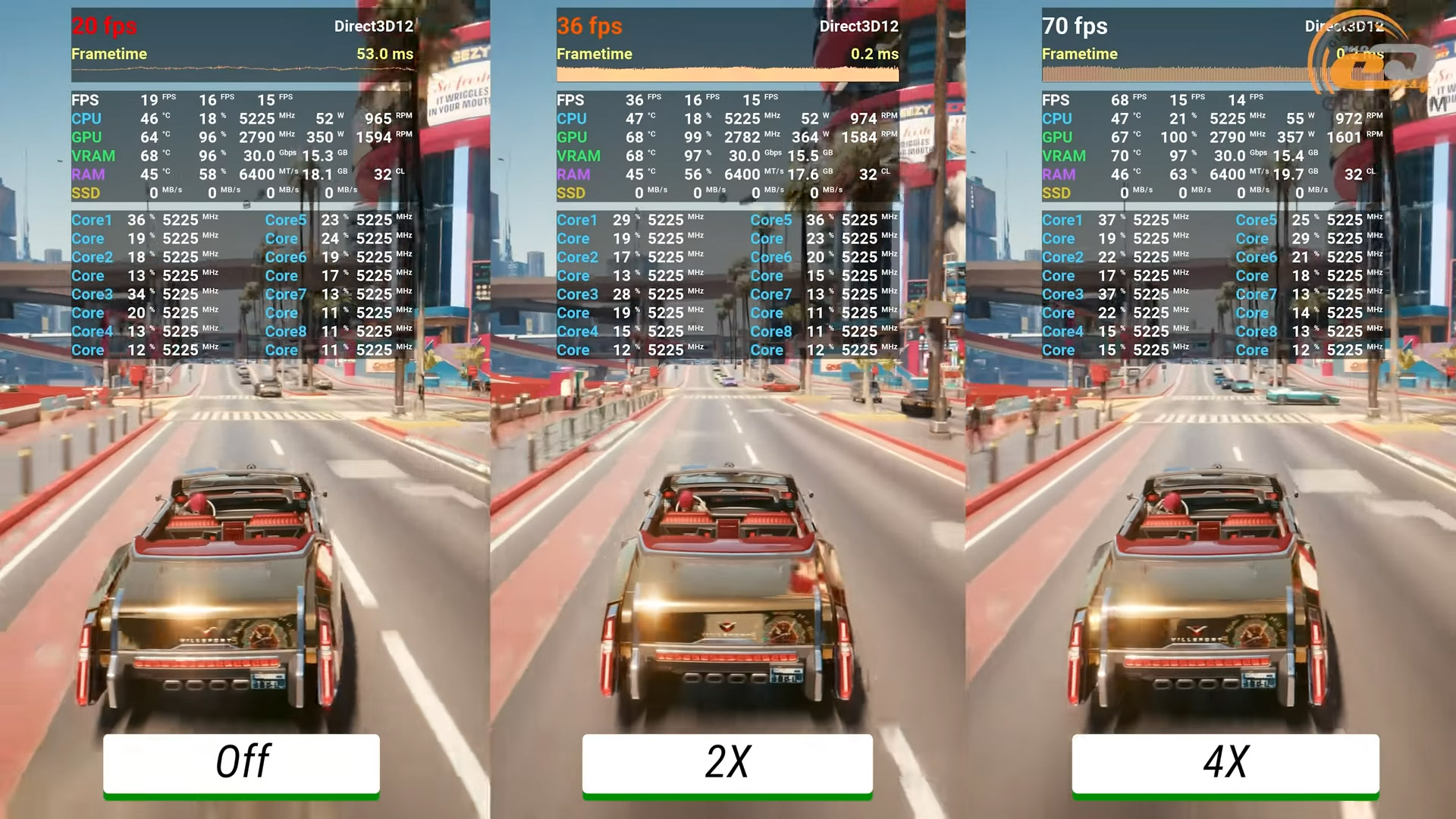
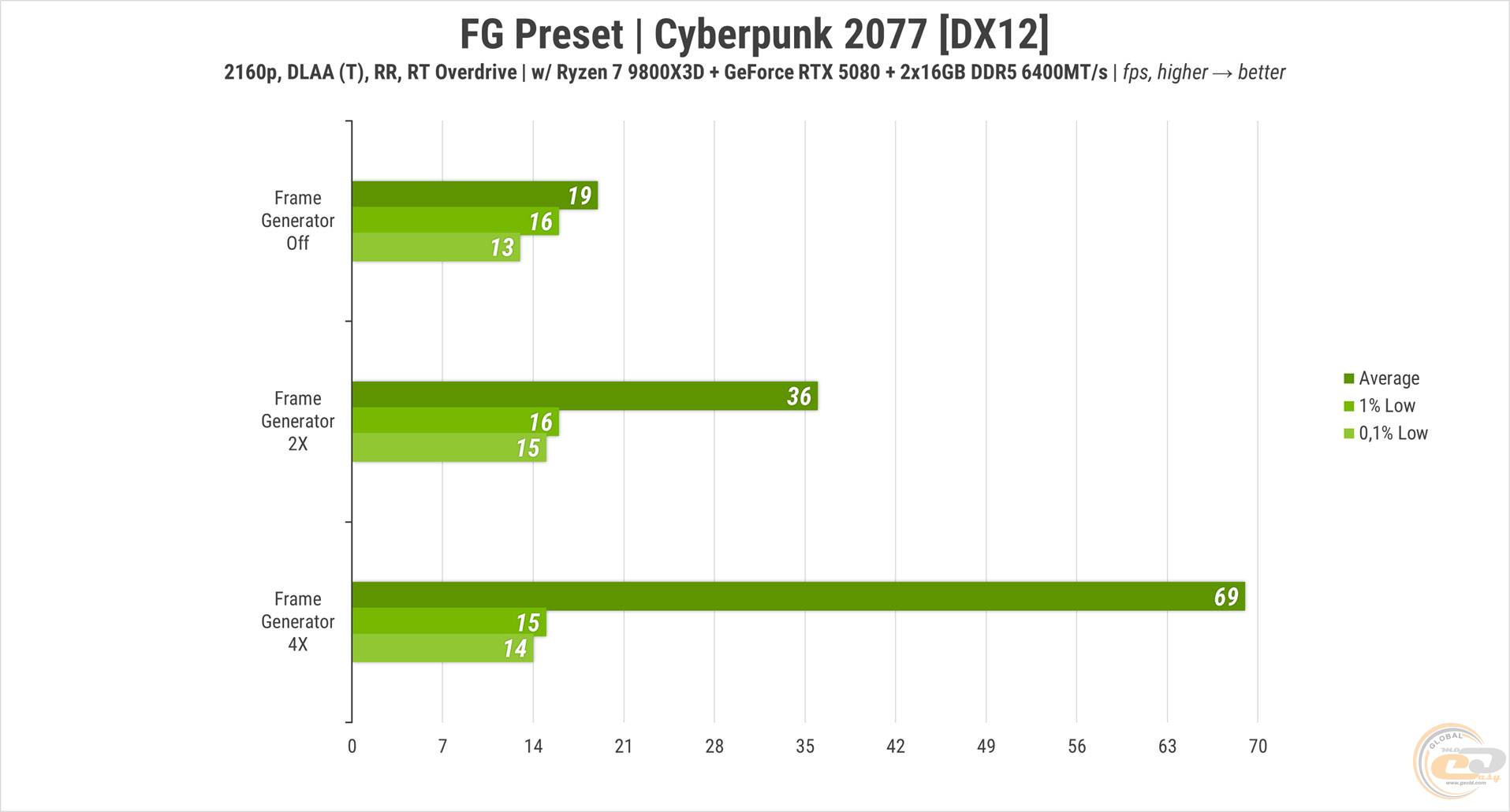
Ще один тест демонструє, як працює генерація кадрів, коли базової частоти оновлення дисплея недостатньо. Переводимо апскейлер у режим DLAA-згладжування й спостерігаємо 19 FPS у середньому без FG — саме те, що потрібно. Далі вмикаємо режими x2 та x4, що дає вже 36 і 69 FPS відповідно.
Але зверніть увагу на артефакти — вони майже всюди. Хоча якщо просто грати й не вдивлятися, спершу можна нічого не помітити.
Підсумки
Отже, якщо оцінювати GeForce RTX 5080 суто за продуктивністю, складається враження, що перед нами не повноцінне нове покоління, а просто прискорена версія попередньої серії. Аж надто мало драйву вона привнесла як у іграх, так і робочих застосунках.
Перевага понад 20% над аналогами минулого покоління – рідкість, а саме такі випадки можна вважати успіхом. Більш-менш непогано новинка виглядала лише на фоні топового рішення від червоних, але й тут хотілося б більшого, особливо з огляду на ціну. На старті продажів вартість перевалює за 70 000 гривень, що суттєво відрізняється від рекомендованих 999 доларів.
Але є й позитивні моменти. Мультигенератор дійсно працює як заявлено і при базовій частоті оновлення близько 60 FPS стає корисним інструментом для високогерцових моніторів. Плюс багато чого змінилося в архітектурному плані, хоч і схоже на те, що роботи по впровадженню нових методів ще багато. Ми неодмінно у найближчих оглядах спробуємо заглибитися у нові технології більш детально, тож не пропустіть!

Що ж до Palit GeForce RTX 5080 GameRock, то вона не просто сподобалась - вона здивувала. Споживаючи 360 Вт, карта утримувала при стресовому навантаженні всього 67 градусів на GPU та 62 на VRAM – це просто чудовий результат. До того ж і дискомфортного шуму вона не створювала. Так, за це доведеться розплачуватися великими габаритами, але часи зараз такі і покращень по цьому напрямку поки не видно.
Автор: Олексій Єрін
Опубліковано : 02-06-2025
| Підписатися на наші канали | |||||

|

|

|

|
||








